Unlabeled LC-MS Workflow¶
This is a tutorial for processing Unlabeled LC/MS data files through El-MAVEN.
Preprocessing¶
msConvert is a command-line/GUI tool that is used to convert between various mass spectroscopy data formats, developed and maintained by proteoWizard. Raw data files obtained from mass spectrometers need to be converted to certain acceptable formats before processing in El-MAVEN.
Input
msConvert supports the following formats:
- .mzXML
- .mzML
- .RAW ThermoFisher
- .RAW Walters
- .d Agilent
- .wiff ABSciex
The settings used for msConvert as a GUI tool are captured in the following screenshots:
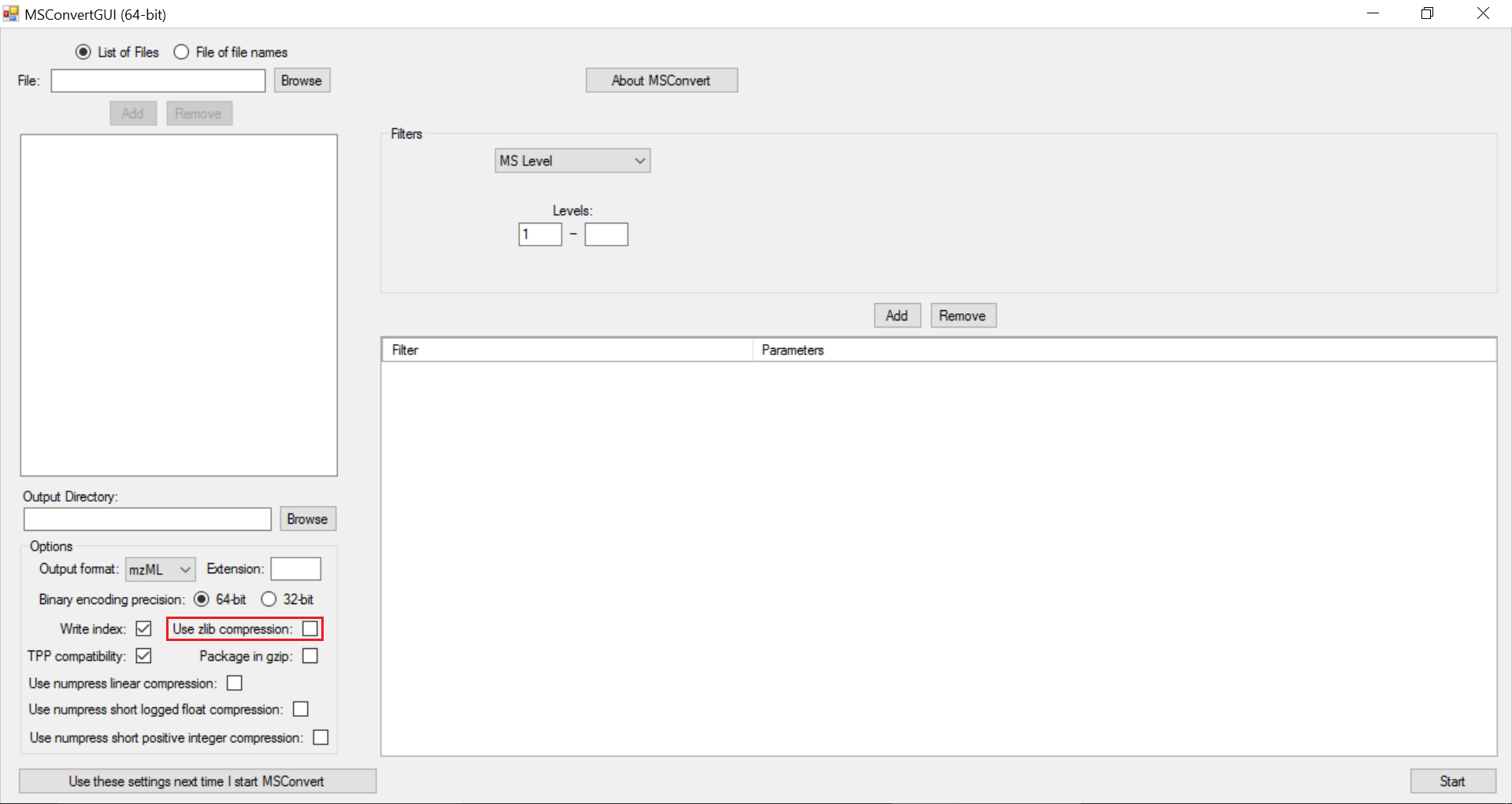
Note
zlib compression is enabled by default in msConvert. El-MAVEN in its current form does not support zlib compression. It is important to uncheck “Use zlib compression” box.
Output
msConvert can convert to an array of different formats but El-MAVEN primarily uses .mzXML and .mzML formats.
Adjust Global Settings¶
Global Settings can be changed from the Options dialog  . There are 9 tabs in the dialog. Each of these tabs has parameters related to a different module in El-MAVEN. For example, a tab for Instrumentation details, a tab for File Import settings etc.
. There are 9 tabs in the dialog. Each of these tabs has parameters related to a different module in El-MAVEN. For example, a tab for Instrumentation details, a tab for File Import settings etc.
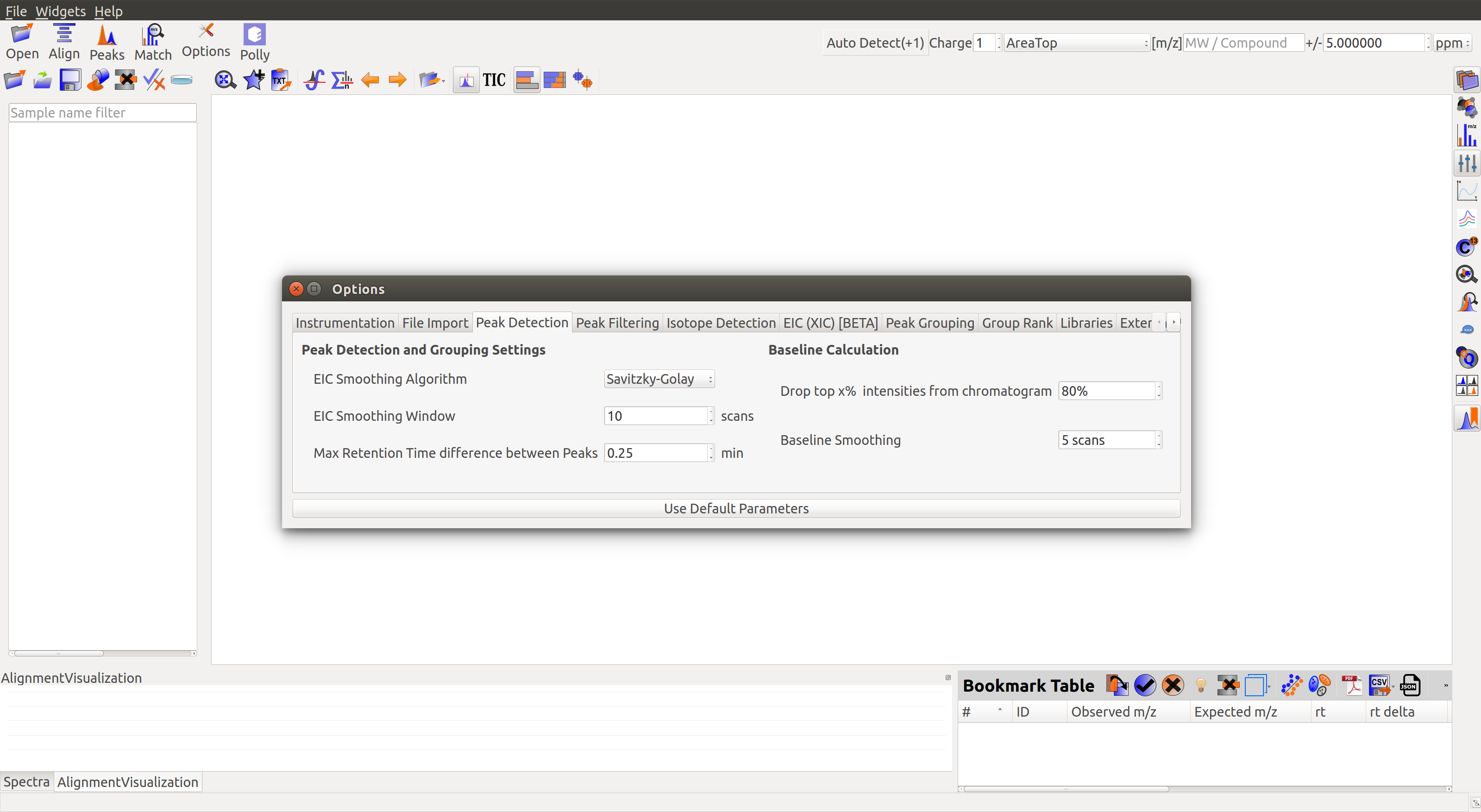
To know more about the functionality of different tabs and their settings, users can see the Widgets page. Please be sure to set the desired settings before processing an input file.
Load Samples¶
Users can go to File in the Menu and click on Load Samples|Projects|Peaks option. Then navigate to the folder containing the sample data, select all .mzXML or .mzML files and click Open. A loading bar displays the progress at the bottom.
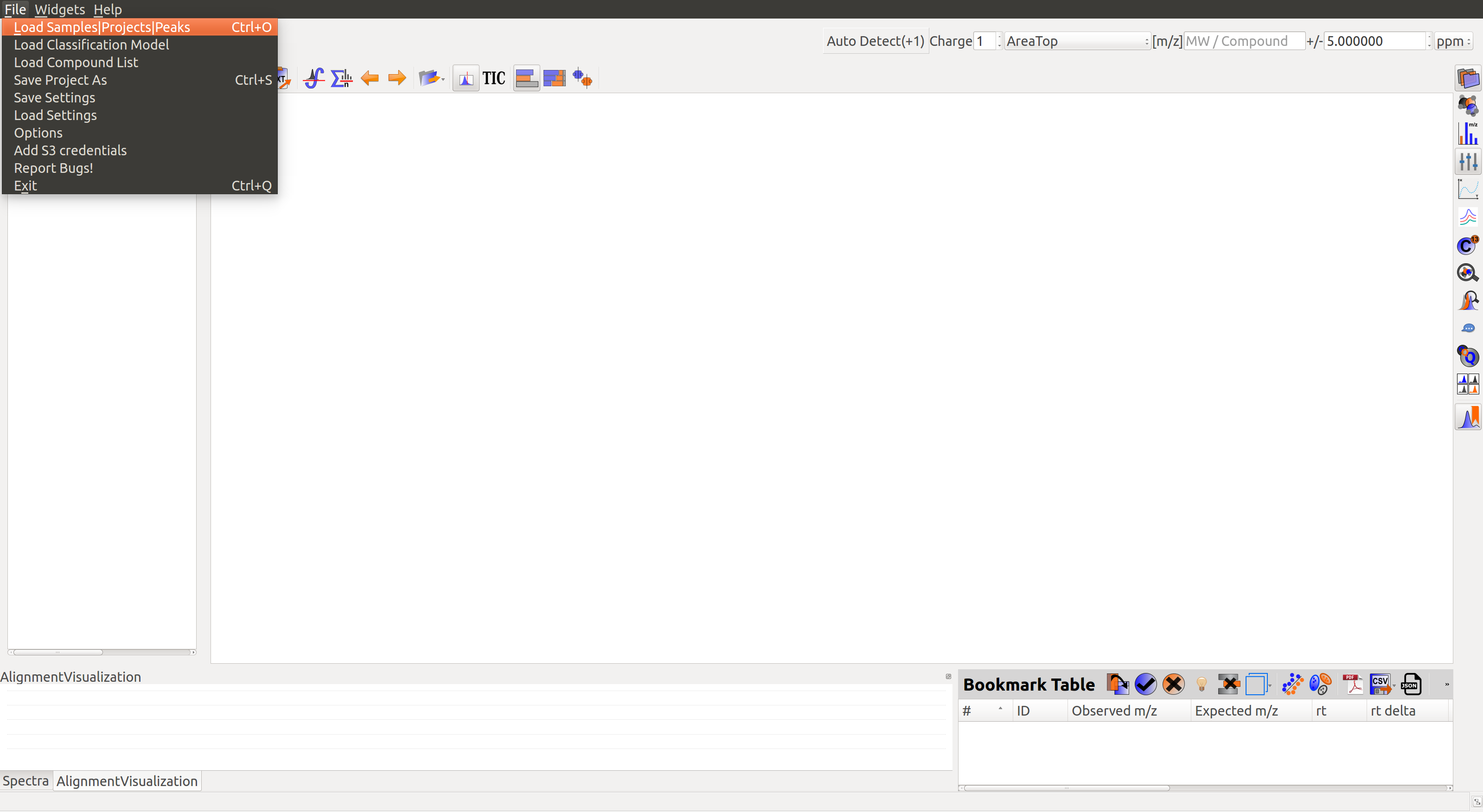
When the samples have loaded, users should see a sample panel on the left side. If it is not displayed automatically, click on the Show Samples Widget button on the toolbar. El-MAVEN automatically assigns a color to every sample. Users can select/deselect any sample by clicking the checkbox on the left of the sample name.
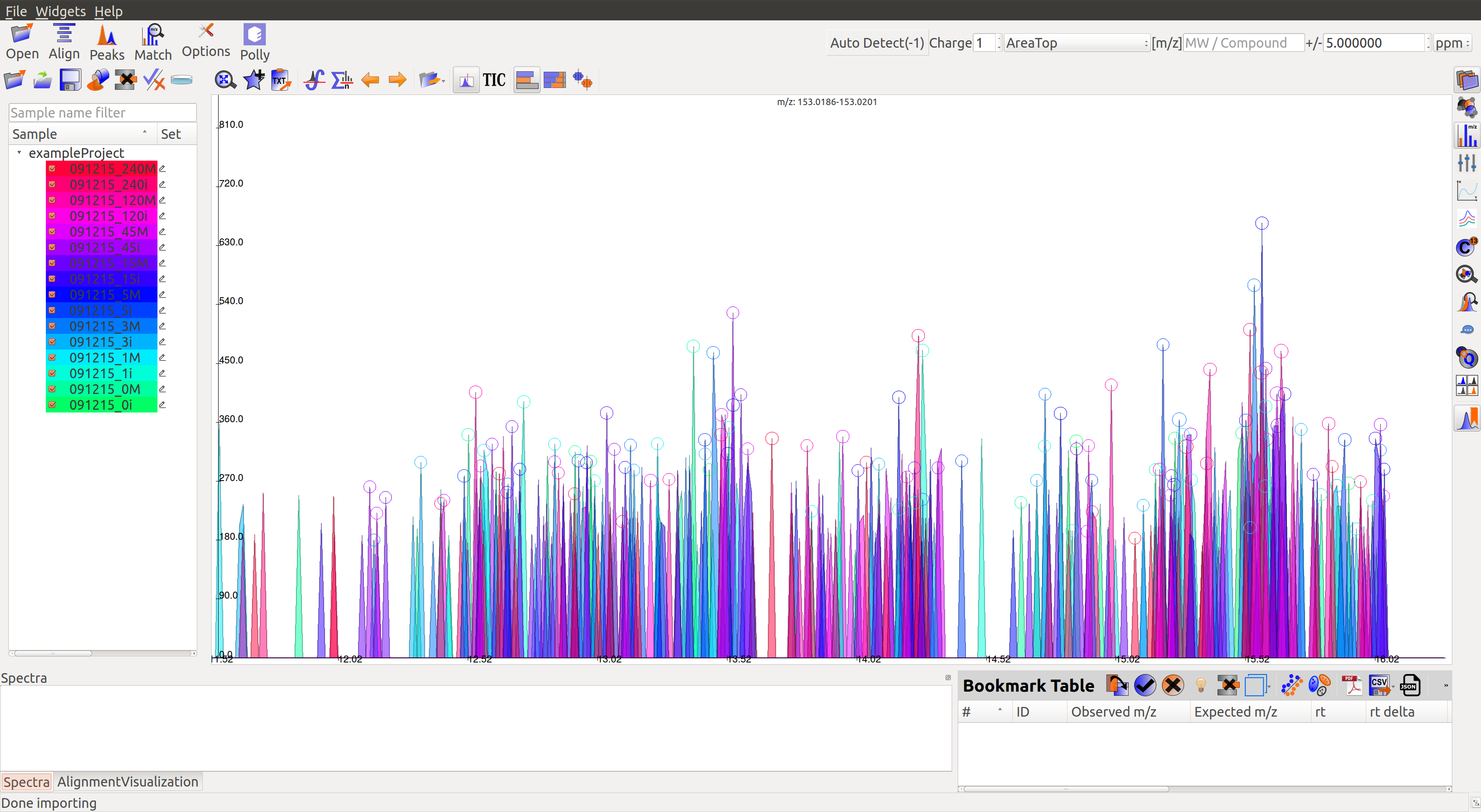
Load Compound Database¶
Users can click on Compounds option in the leftmost menu, navigate to the folder containing the standard database file, select the appropriate .csv file and click Open. Alternatively, users may use any of the default files loaded on start-up.
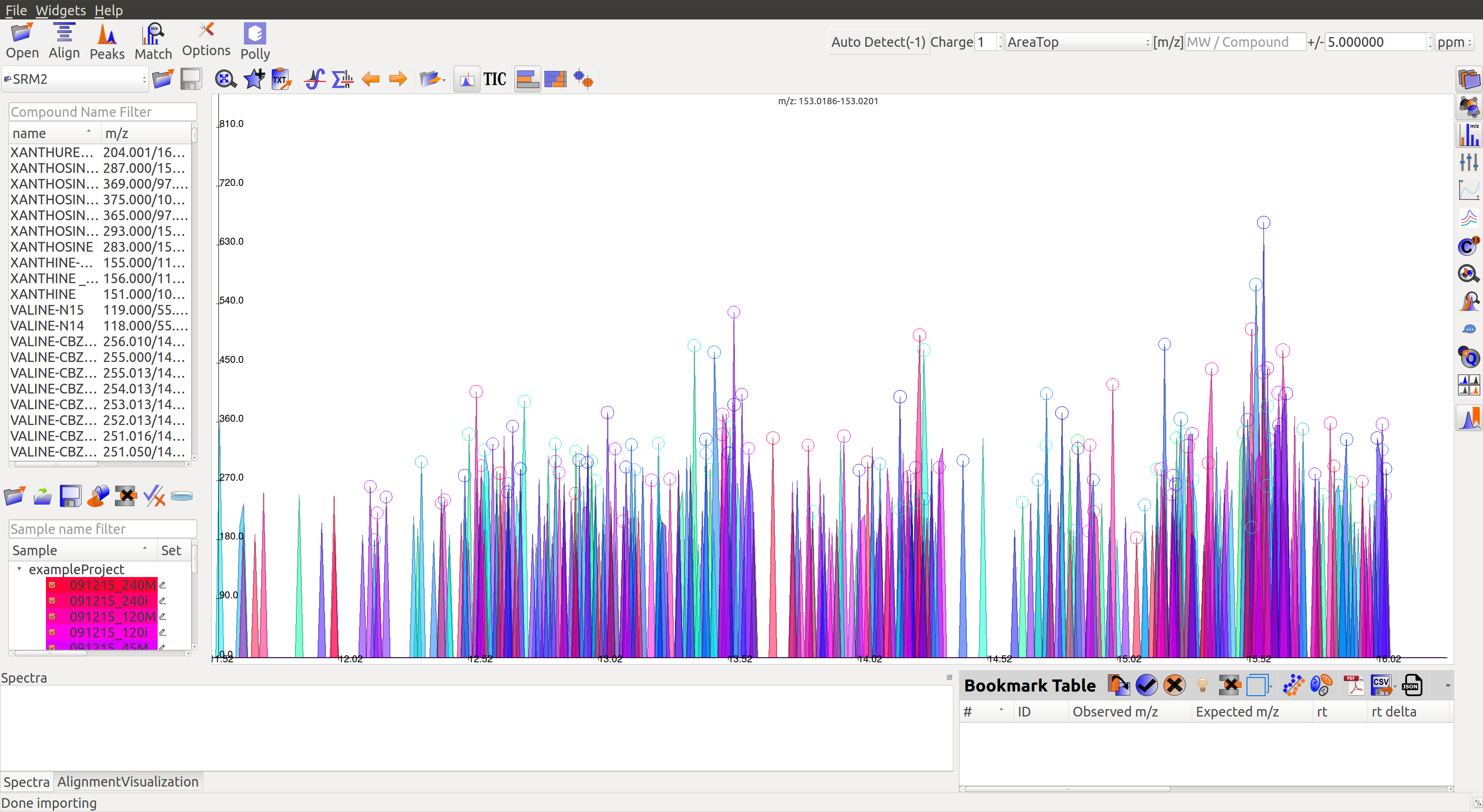
This is a sample Compound Database:
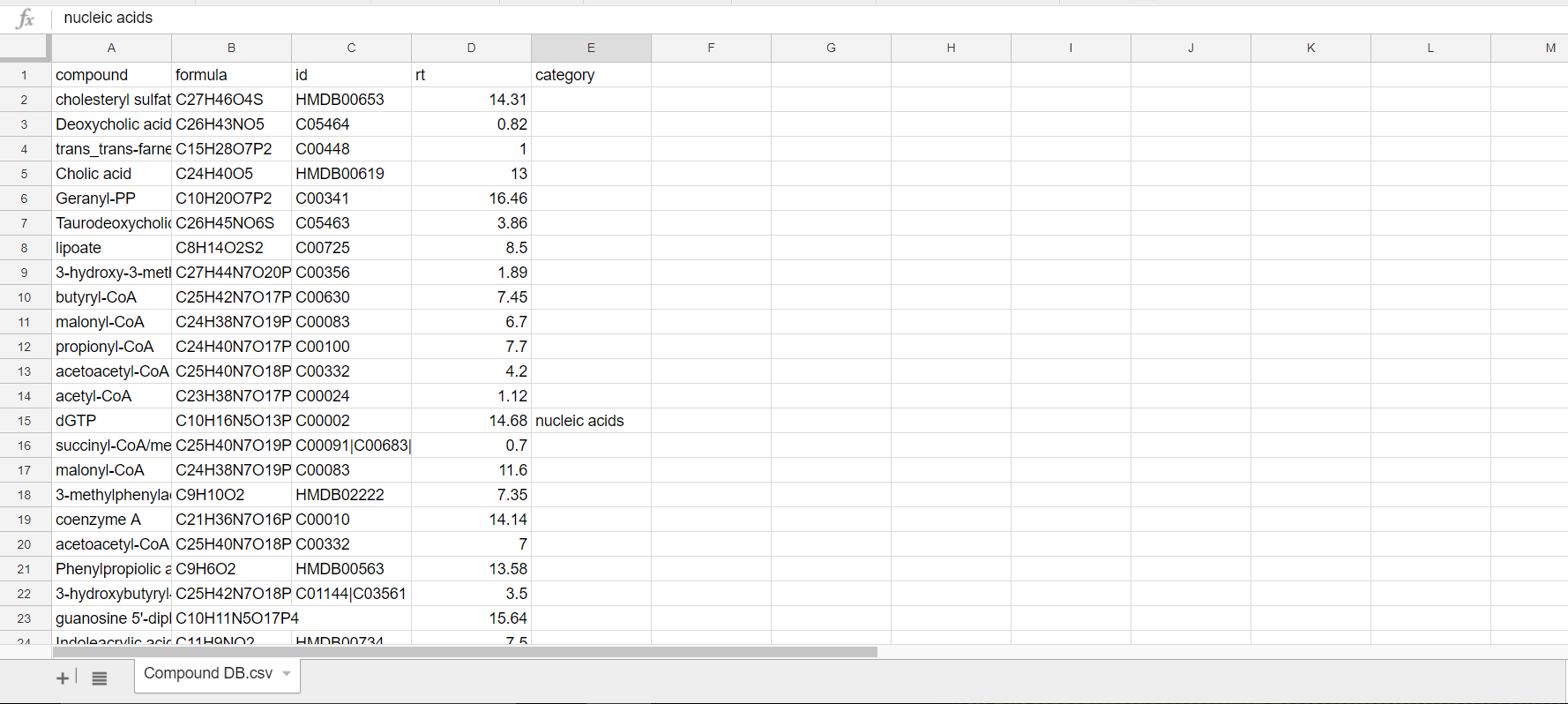
It lists all metabolite names, chemical formula, HMDB ID, and the class/category of compounds they belong to (if known).
Mark Blanks¶
Users can mark the blanks by selecting the blank samples from the list on screen, and clicking on the Set as a Blank Sample icon  in Samples menu.
in Samples menu.
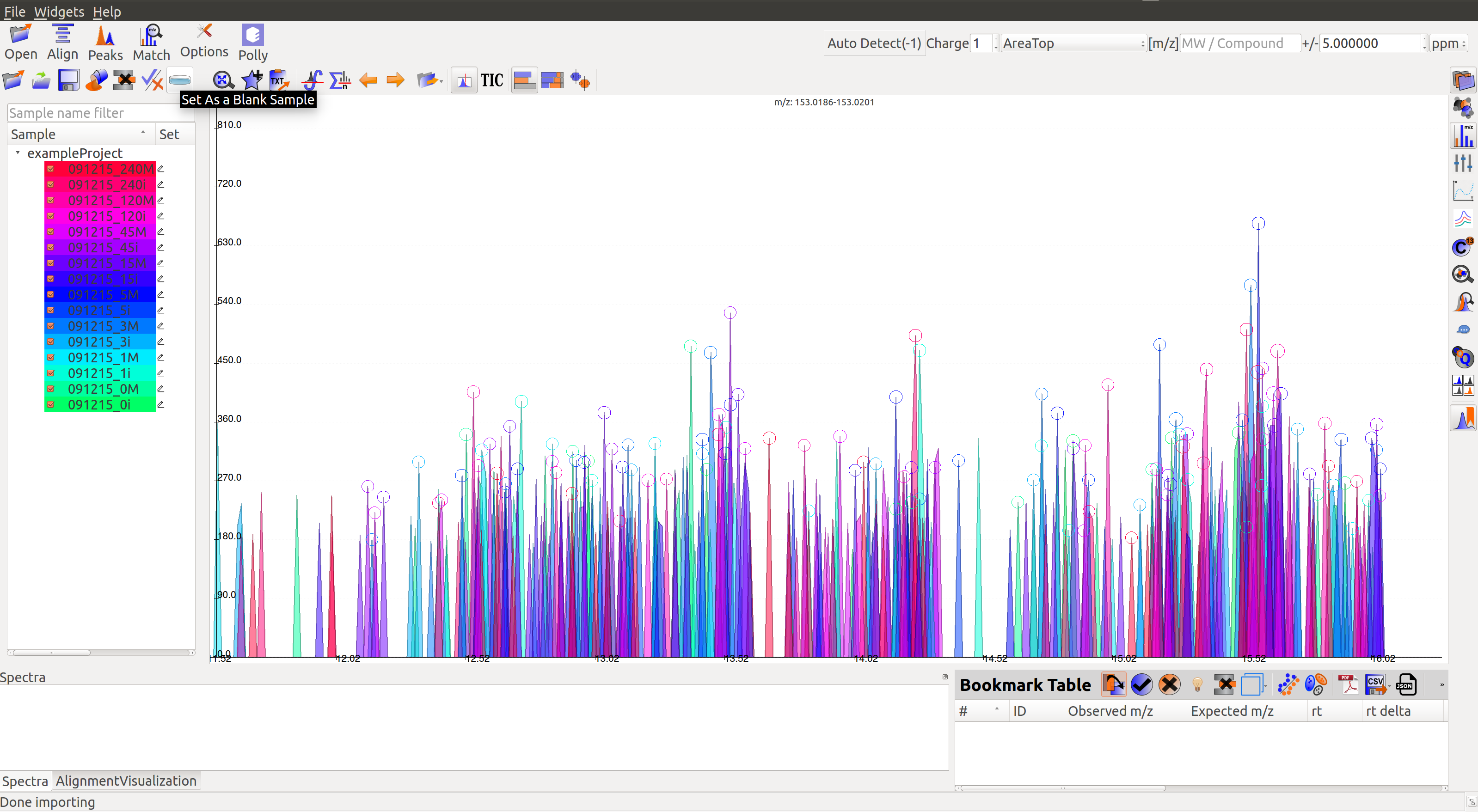
Multiple blanks can be marked together. The blanks will appear black as shown in the image below:
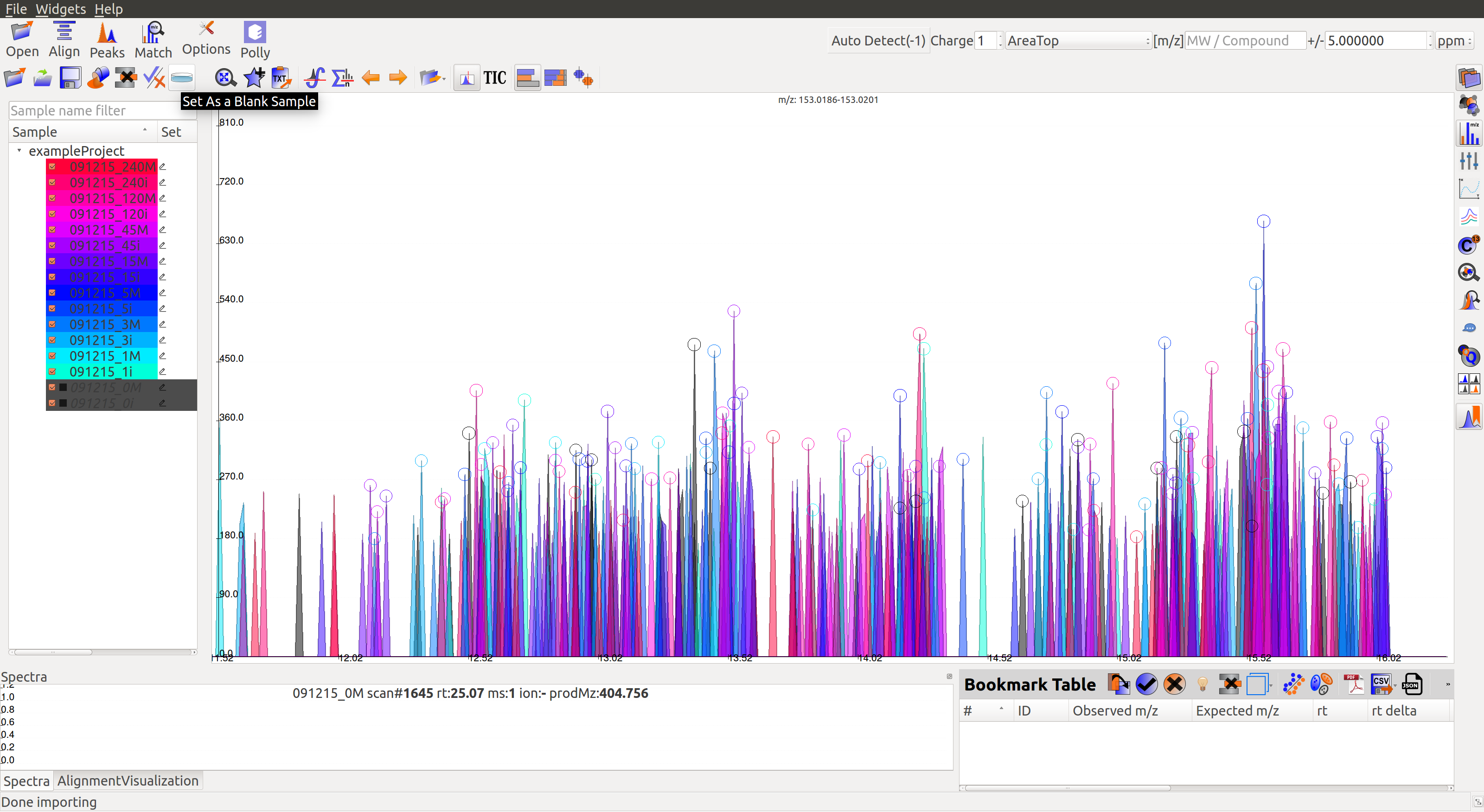
Alignment¶
Prolonged use of the LC column can lead to a drift in retention time across samples. Alignment shifts the peak retention time in every sample to correct for this drift and brings the peaks closer to median retention time of the group.
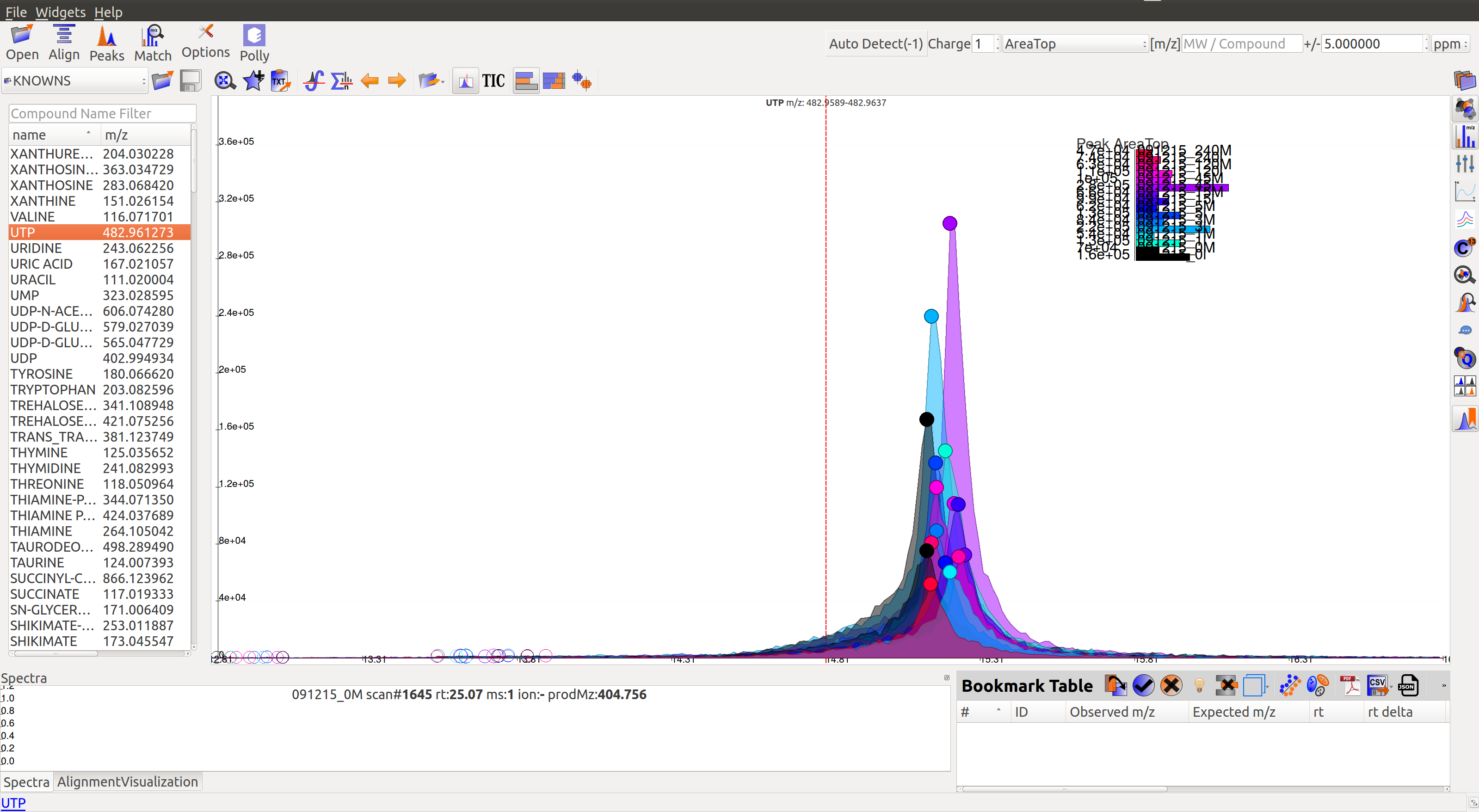
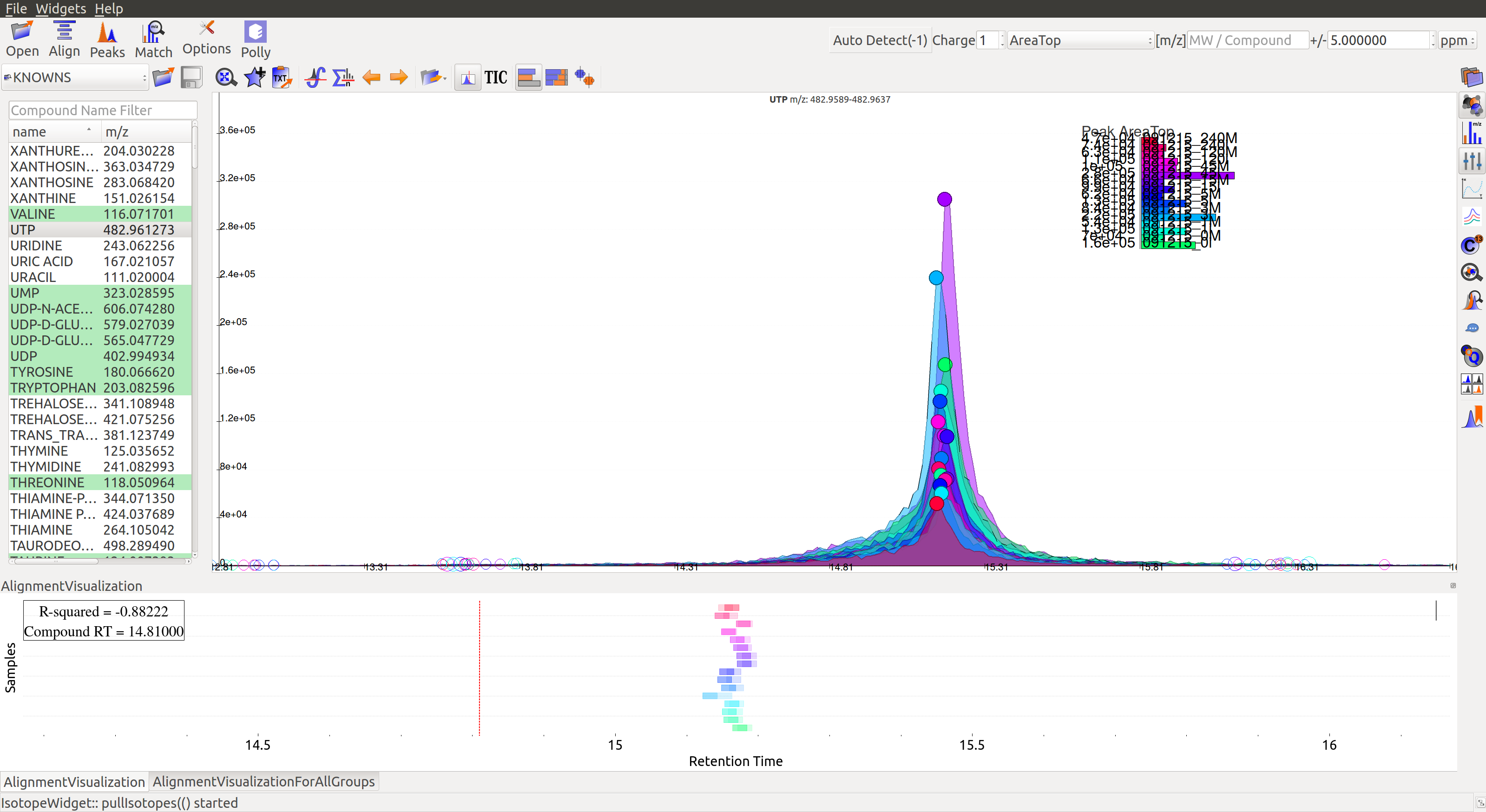
In the above image, EIC for a UTP group is displayed. If the samples were aligned, all peaks would lie at the same retention time. Since this is not the case, the samples need to be aligned.
Alignment visualization  can be used to judge the extent of deviation from median retention time.
can be used to judge the extent of deviation from median retention time.
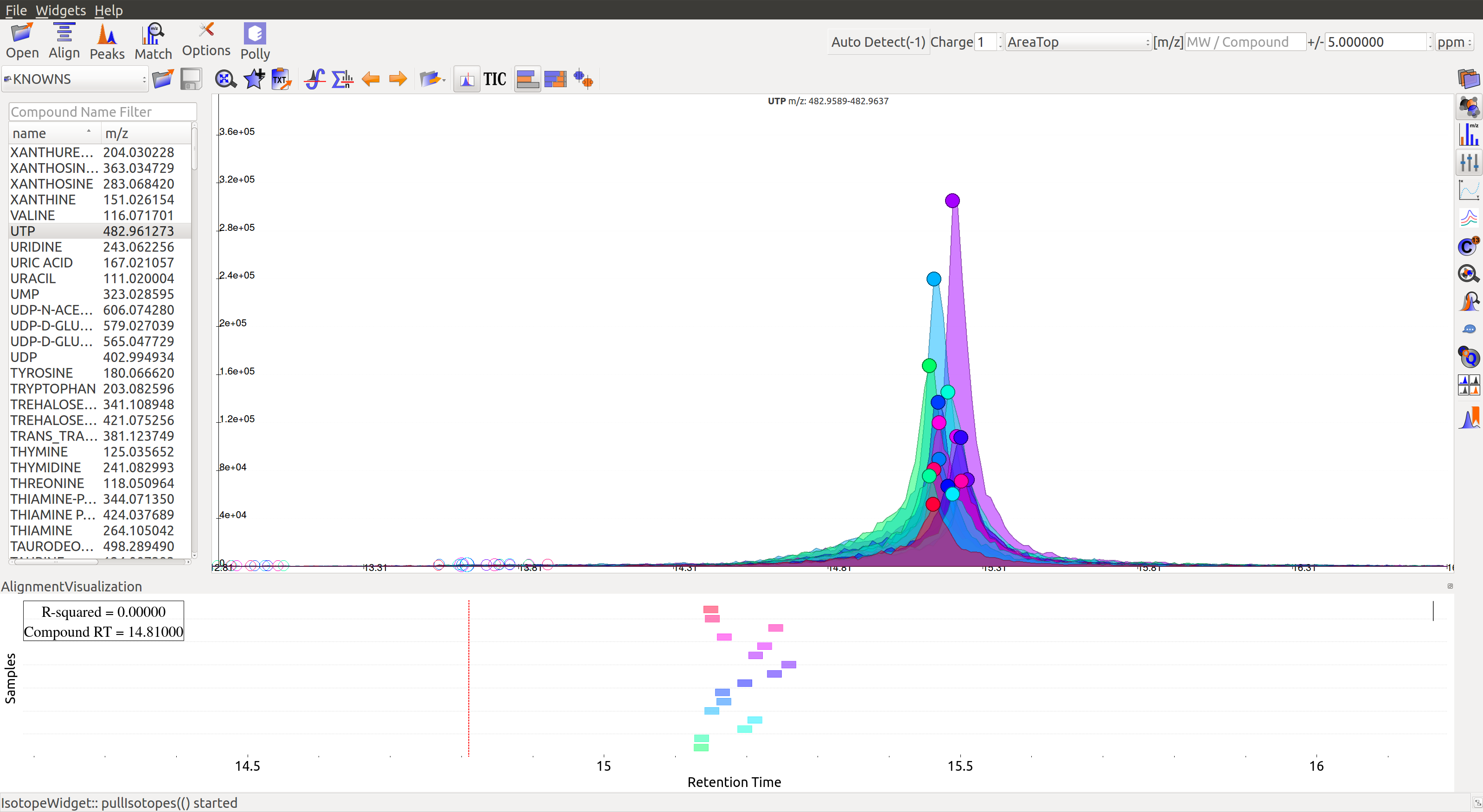
In the above visualization, each box represents a peak from the selected group at its current retention time. Samples are said to be perfectly aligned when all peak boxes lie on the same vertical axis. The peaks are considerably scattered in the above image and therefore the samples should be aligned for better grouping of peaks.
Perform Alignment
Alignment settings can be adjusted using the Align button  . This example was aligned with Poly fit algorithm with default parameters.
. This example was aligned with Poly fit algorithm with default parameters.
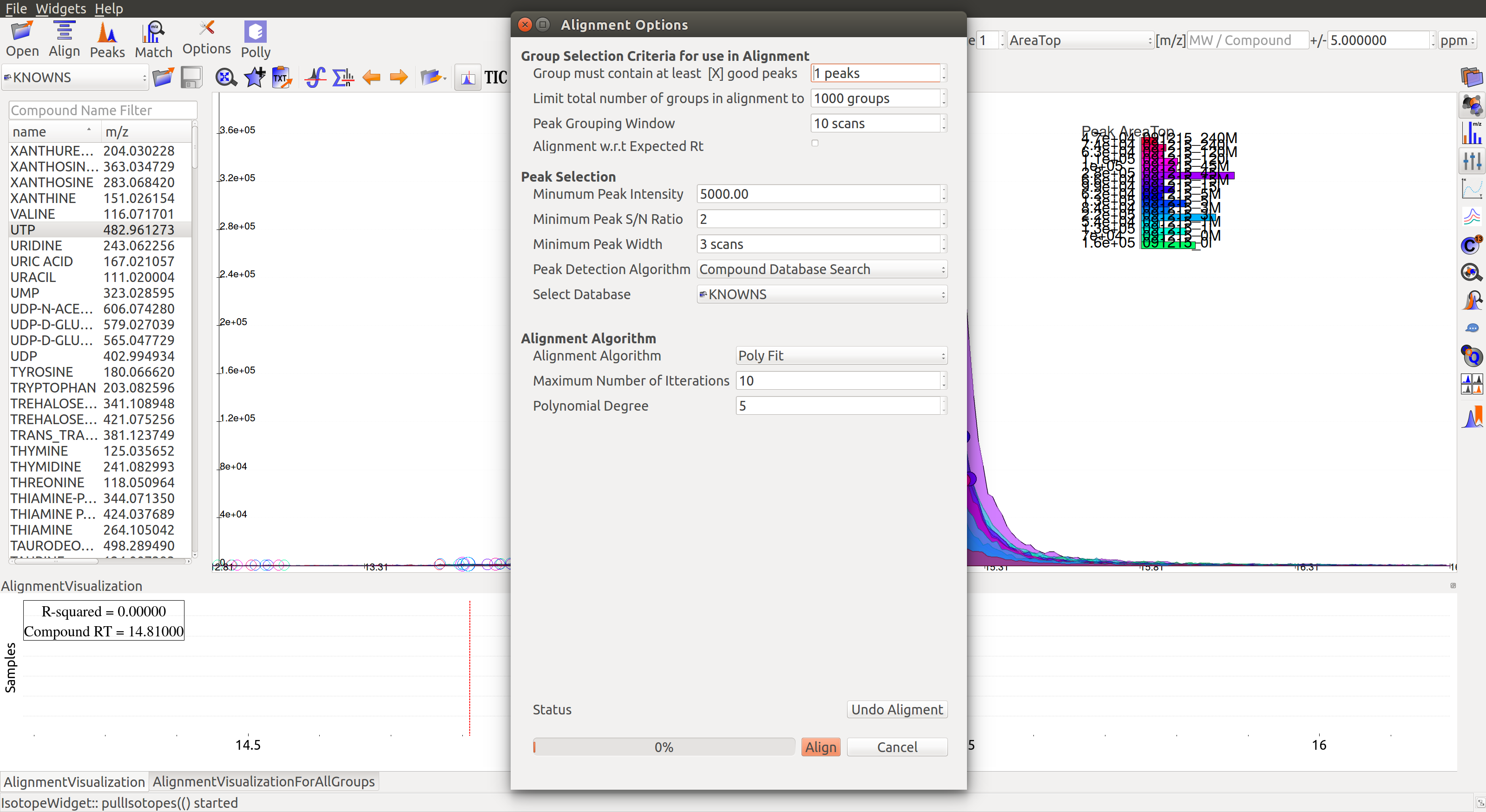
Post-alignment the peaks in the group should appear closer to the median retention time of the group.
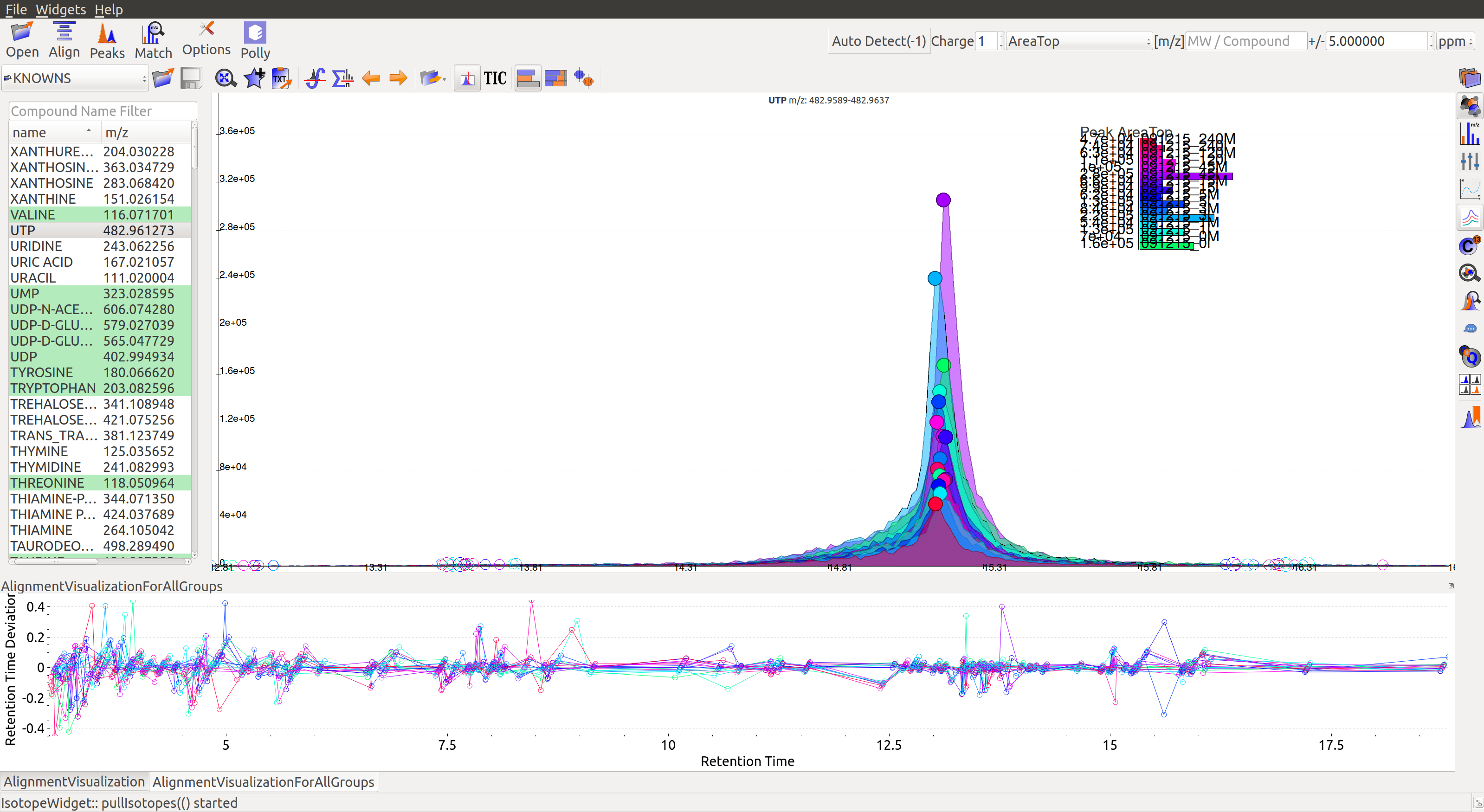
Pre-alignment, the peaks were considerably scattered while the aligned peaks lie nearly on the same axis. Users can run alignment again with different parameters if required (or with a different algorithm). Further details on Alignment settings are available on the Widgets page.
Peak Grouping¶
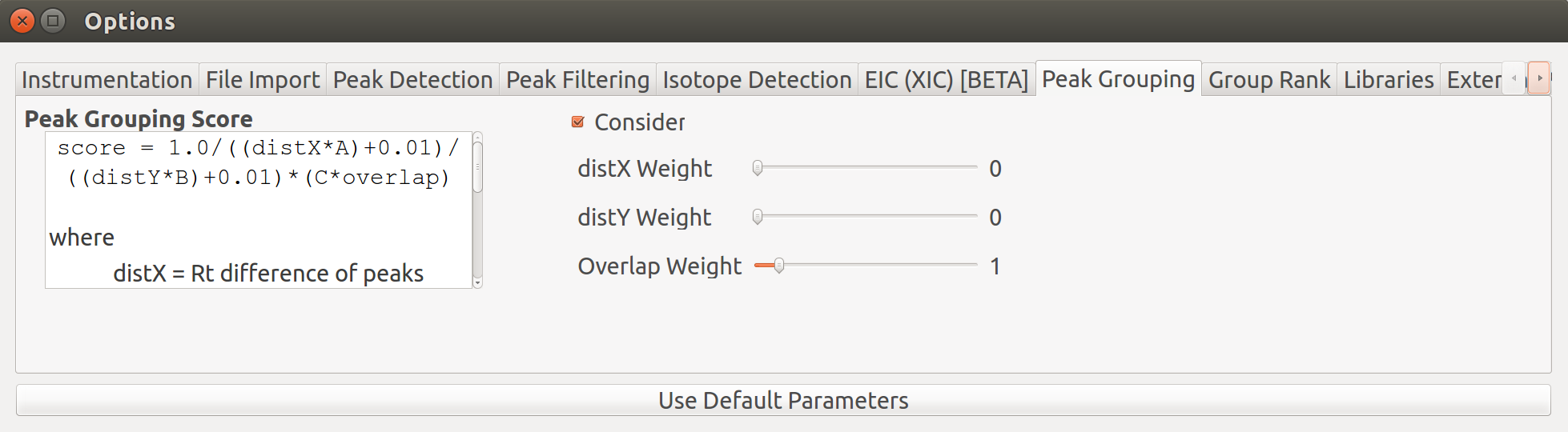
Peak grouping is an integral part of the El-MAVEN workflow that categorizes all detected peaks into groups on the basis of certain user-controlled parameters. A group score is calculated for every peak during the process. The formula for this score takes into account the difference in retention time, intensities between peaks (smaller difference leads to a better score) and any existing overlap between them (higher extent of overlap leads to better score). All three parameters have certain weights attached to them that can be controlled by the users. The formula for the score is shown in the image. More details on it can be found on the Widgets page.
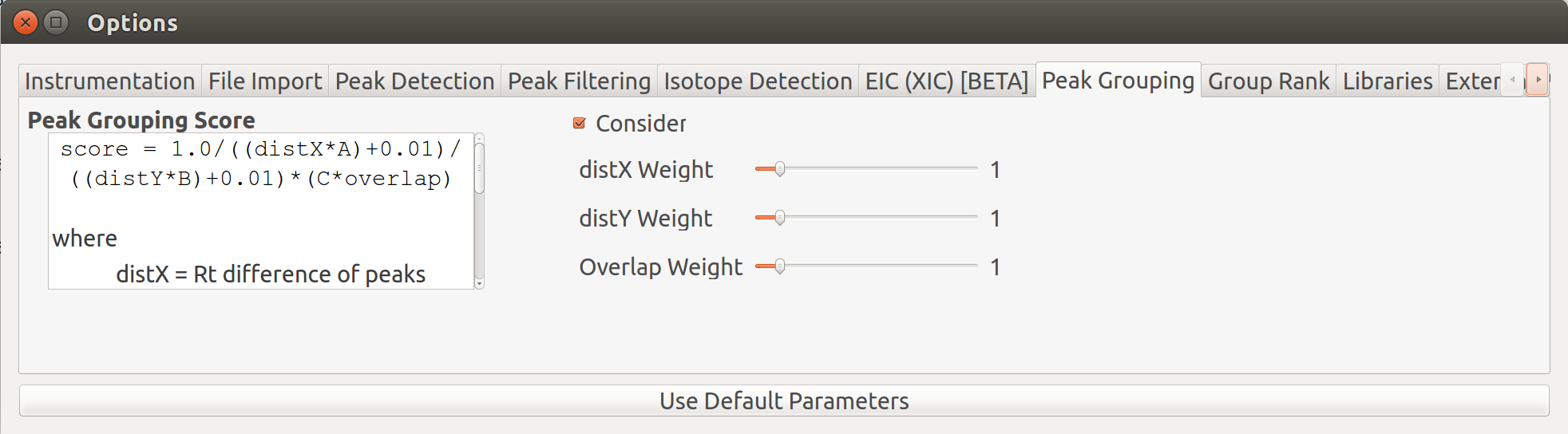
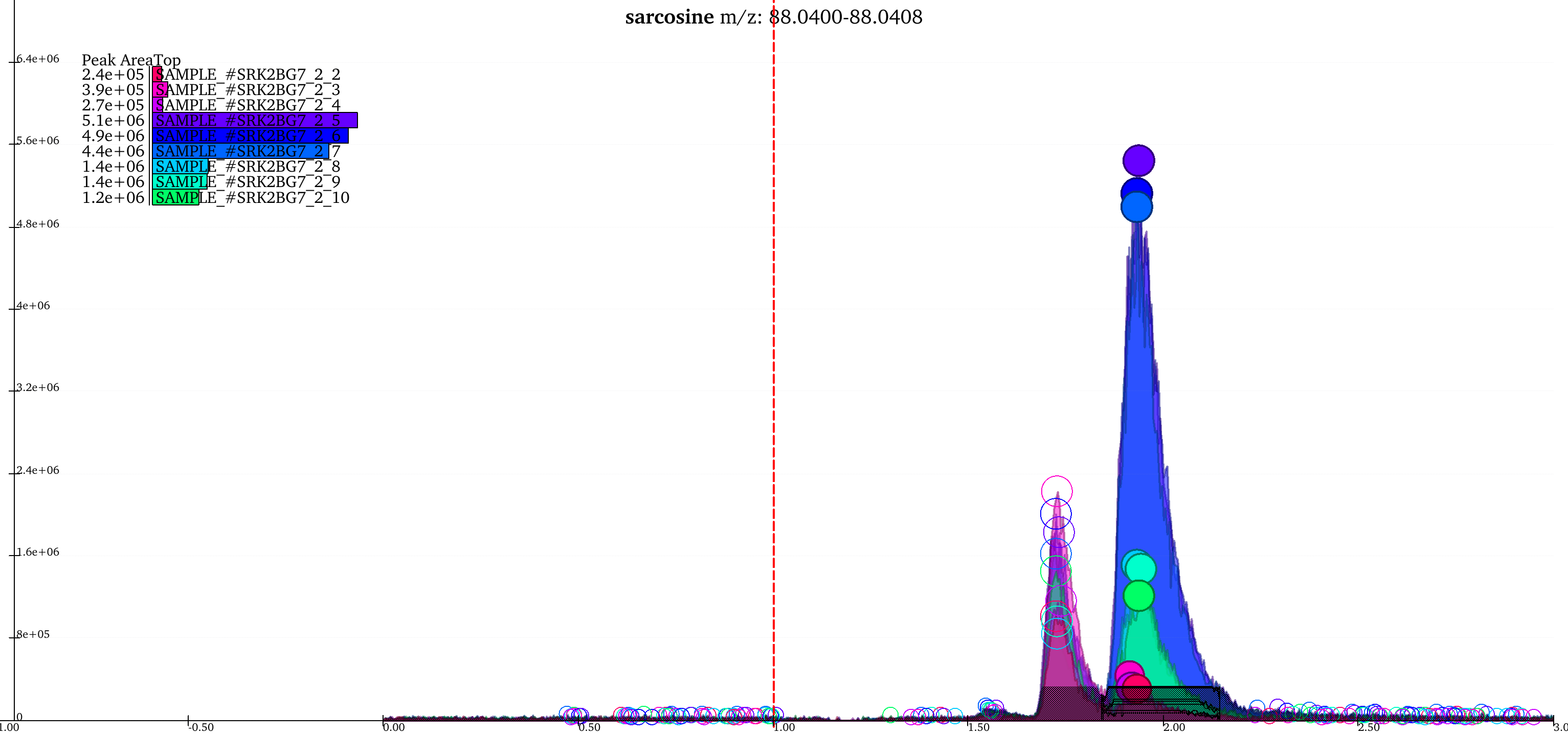
The above image shows two groups in the EIC window. The highlighted (solid circles) peaks belong to group A, the peaks to its left with empty circles belong to another group B. The short peaks in group A that are close to the baseline and peaks in group B come from the same samples. Additionally, the high intensity peaks of group A have a similar peak shape to group B peaks. These peaks might have been wrongly classified into separate groups because of the difference in retention time range of the two sets of peaks. The weights attached to difference in retention time and intensities, and extent of overlap can be adjusted for better grouping.
Grouping parameters can be changed from the Options dialog .
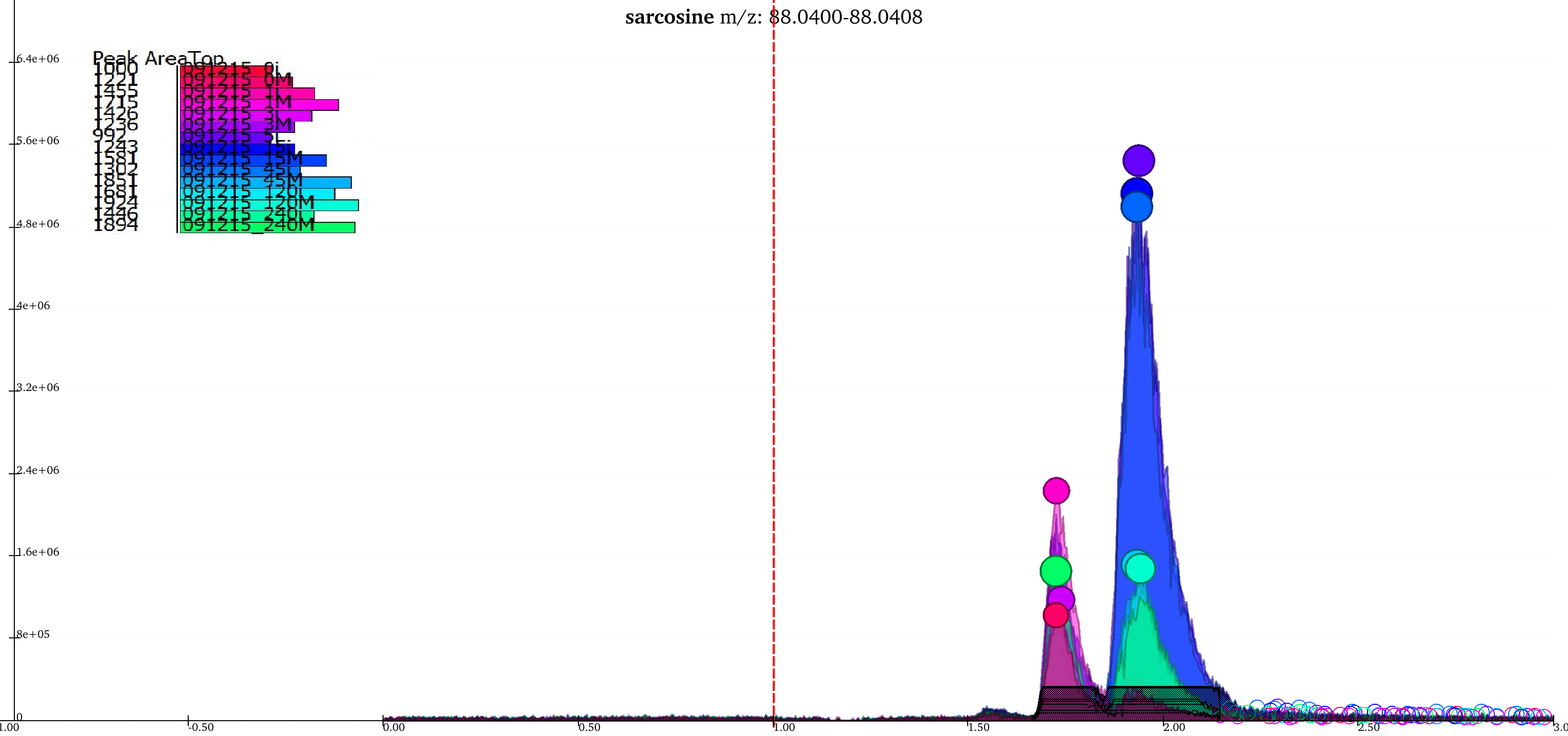
Giving less priority to difference in retention time and intensities results in the two groups being merged into a single group while the peaks that lay close to the baseline are no longer classified as valid peaks.
Baseline¶
When measuring a number of peaks, it is often more effective to subtract an estimated baseline from the data. This baseline should be set where ideally no peaks occur. Although sometimes the program sets a particular baseline such that one or more peaks occur below that baseline value. In the following image, the dashed line represents each baseline:
The corresponding peaks are indicated with solid circles:
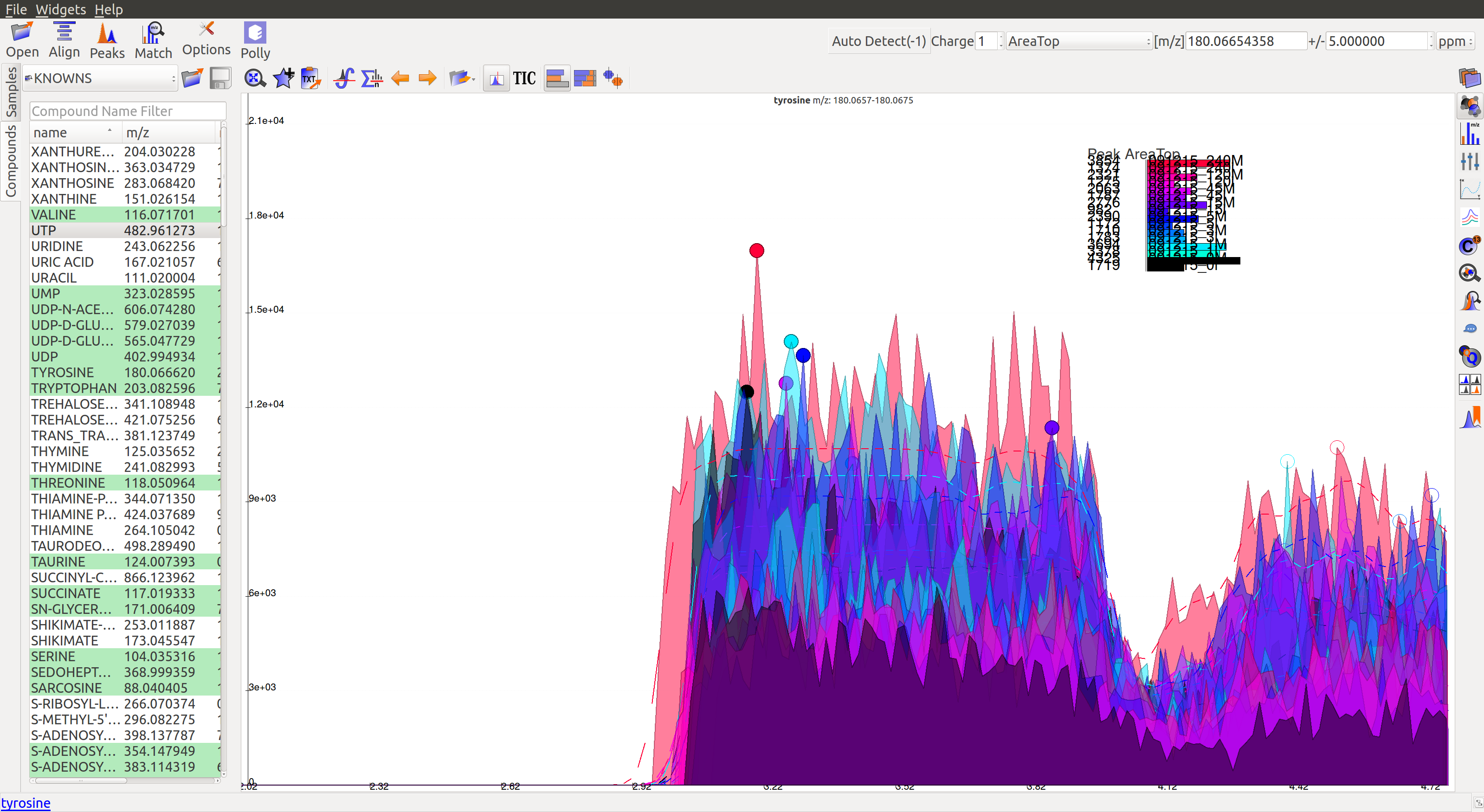
The baseline correction can be done in the Peak Detection tab by clicking on Options button:
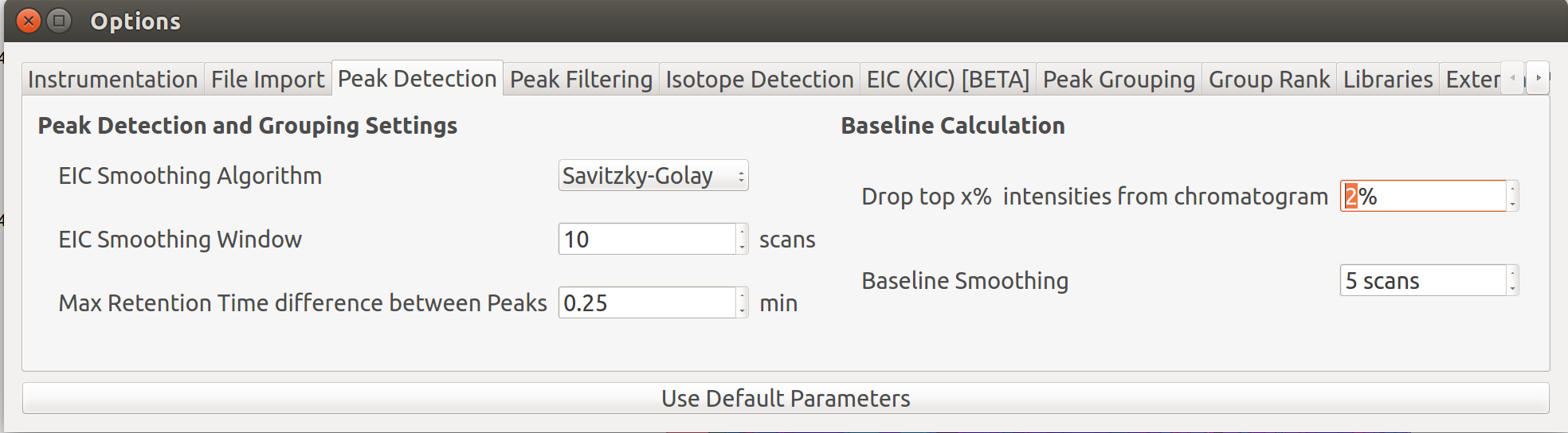
Further details on settings can be accessed here.
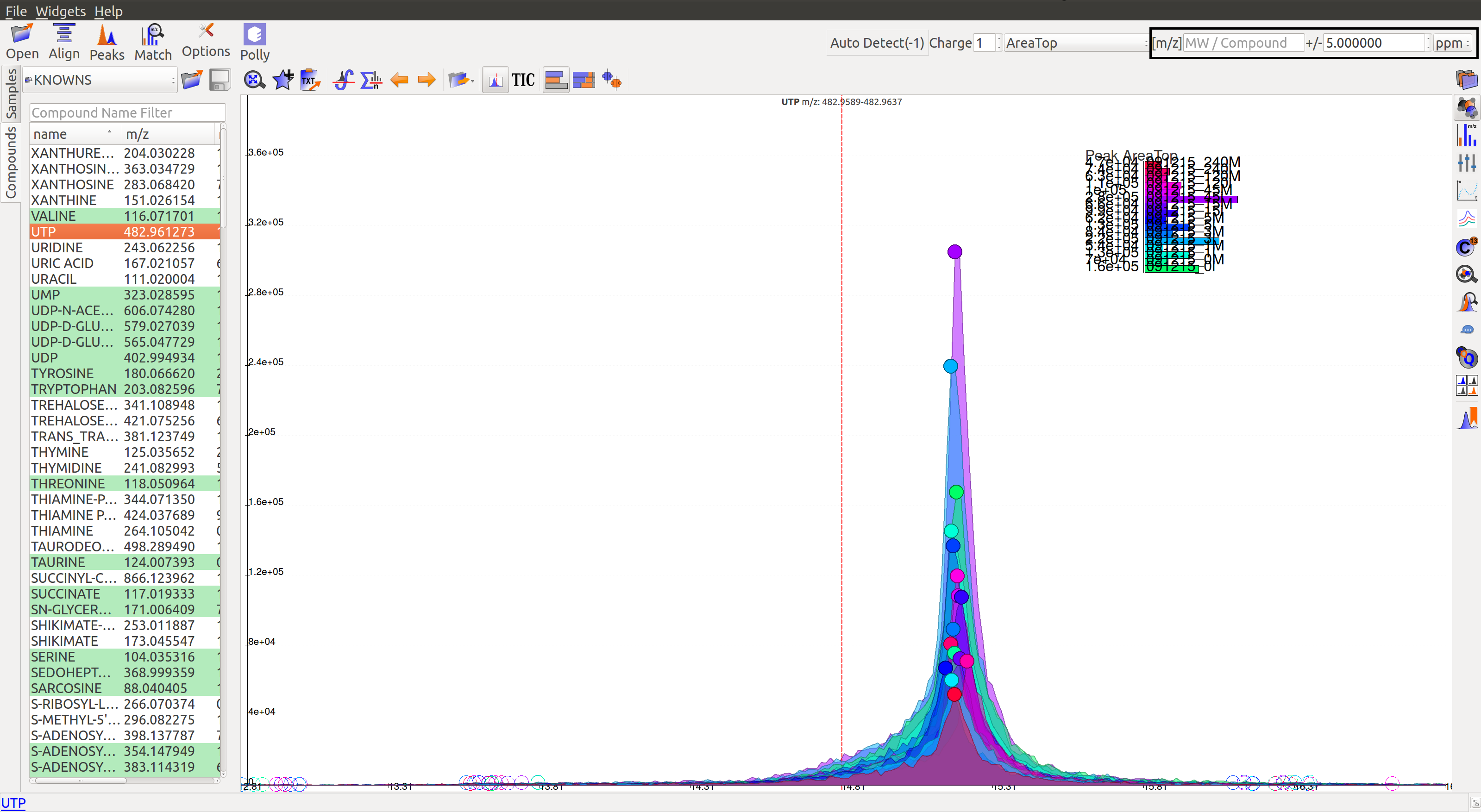
The m/z option scans the groups to find any specific m/z value and plot its corresponding EIC. The +/- option to its right is to specify the expected mass resolution error in parts per million (ppm).
Mass Spectra¶
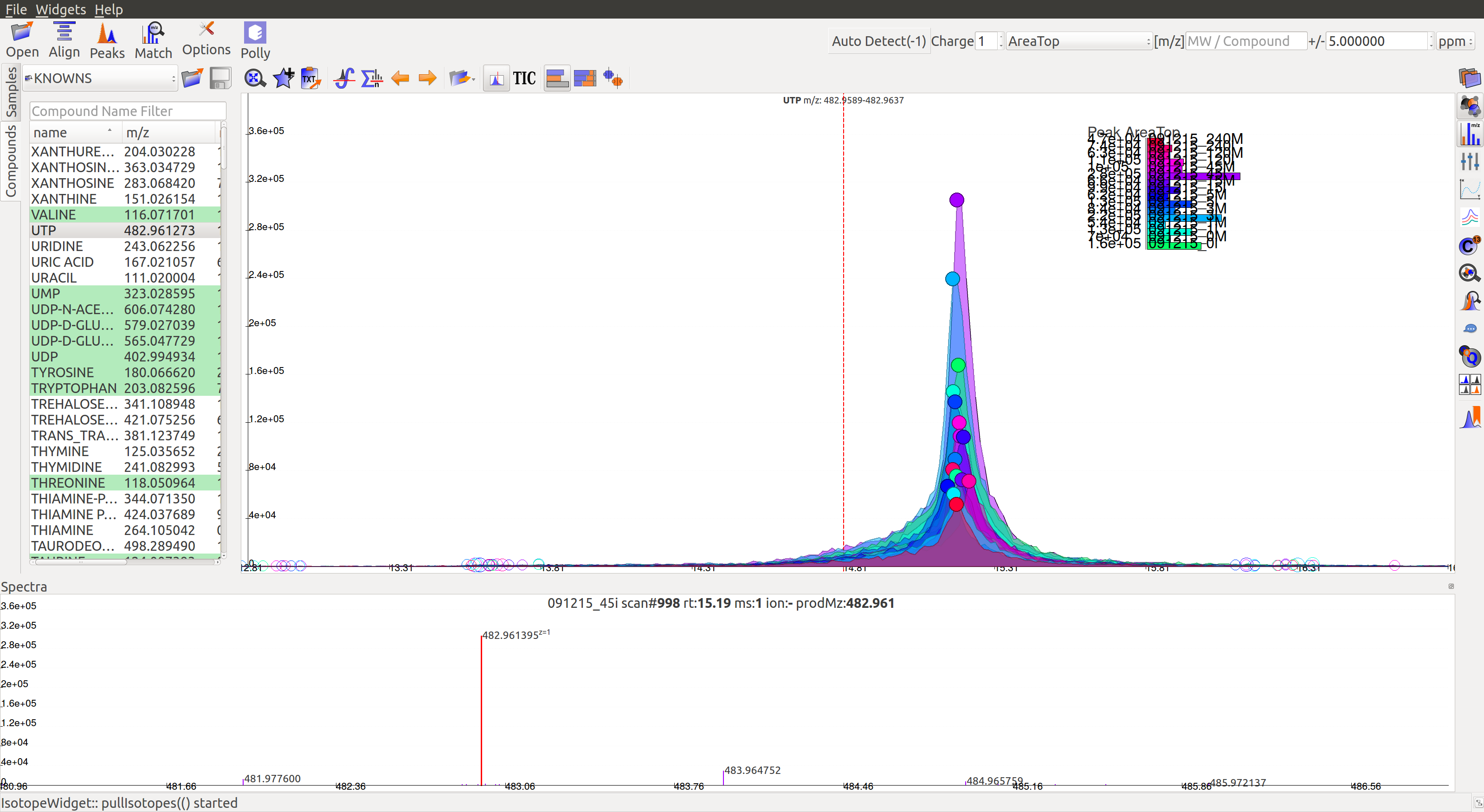
Mass Spectra Widget  displays each peak, its mass, and intensity for a scan. As the widget shows all detected masses in a scan, the ppm window for the EIC and consequently grouping can be adjusted accordingly. This feature is especially useful for MS/MS data and isotopic detection.
displays each peak, its mass, and intensity for a scan. As the widget shows all detected masses in a scan, the ppm window for the EIC and consequently grouping can be adjusted accordingly. This feature is especially useful for MS/MS data and isotopic detection.
Peak Curation¶
There are multiple ways to curate peaks in El-MAVEN, though following are the two broad workflows:
1. Manual Peak Curation using Compound DB widget
To use manual curation using the compound DB widget, users have to iterate over all the compounds in the compound DB on the extreme left of the window, as highlighted in the image below.
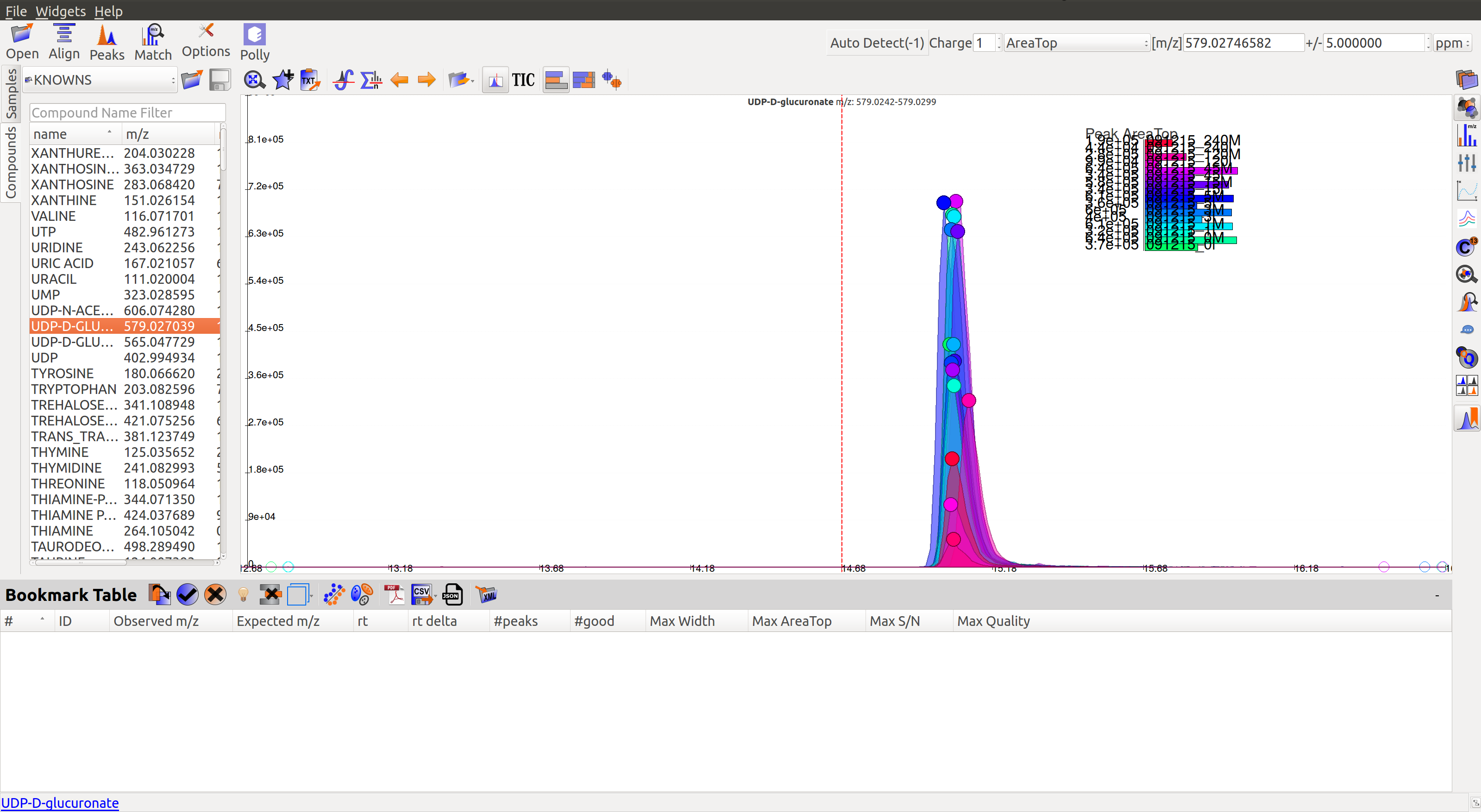
Once on a compound, El-MAVEN shows the highest ranked group for that m/z. Users can now choose a group or reject it.
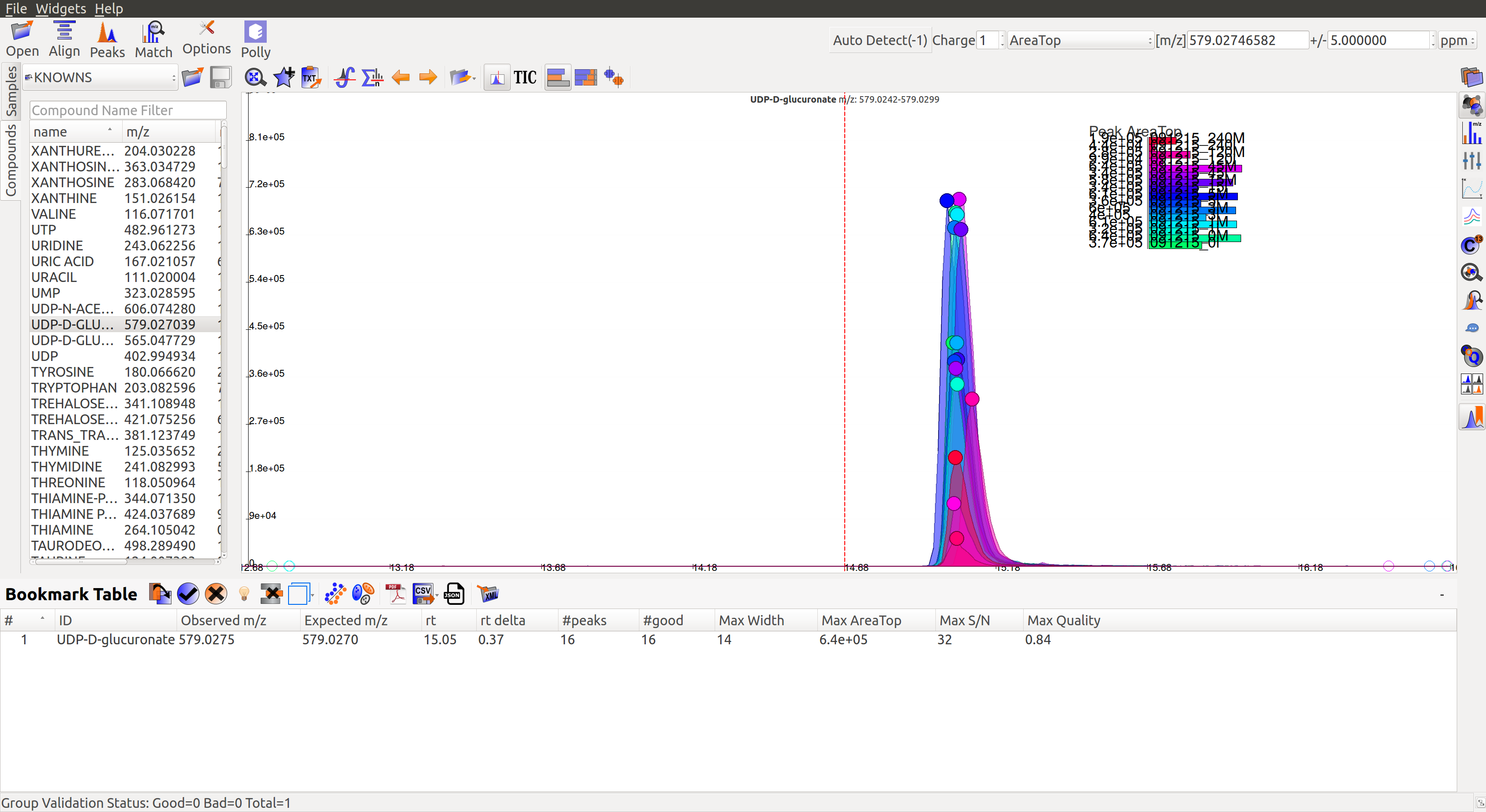
First, users need to double click on the peak group of their choice. This will get the retention time line to the median of the group and also add the metabolite to the bookmarks table (as shown in the image below). Users can read more about the bookmarks table here.
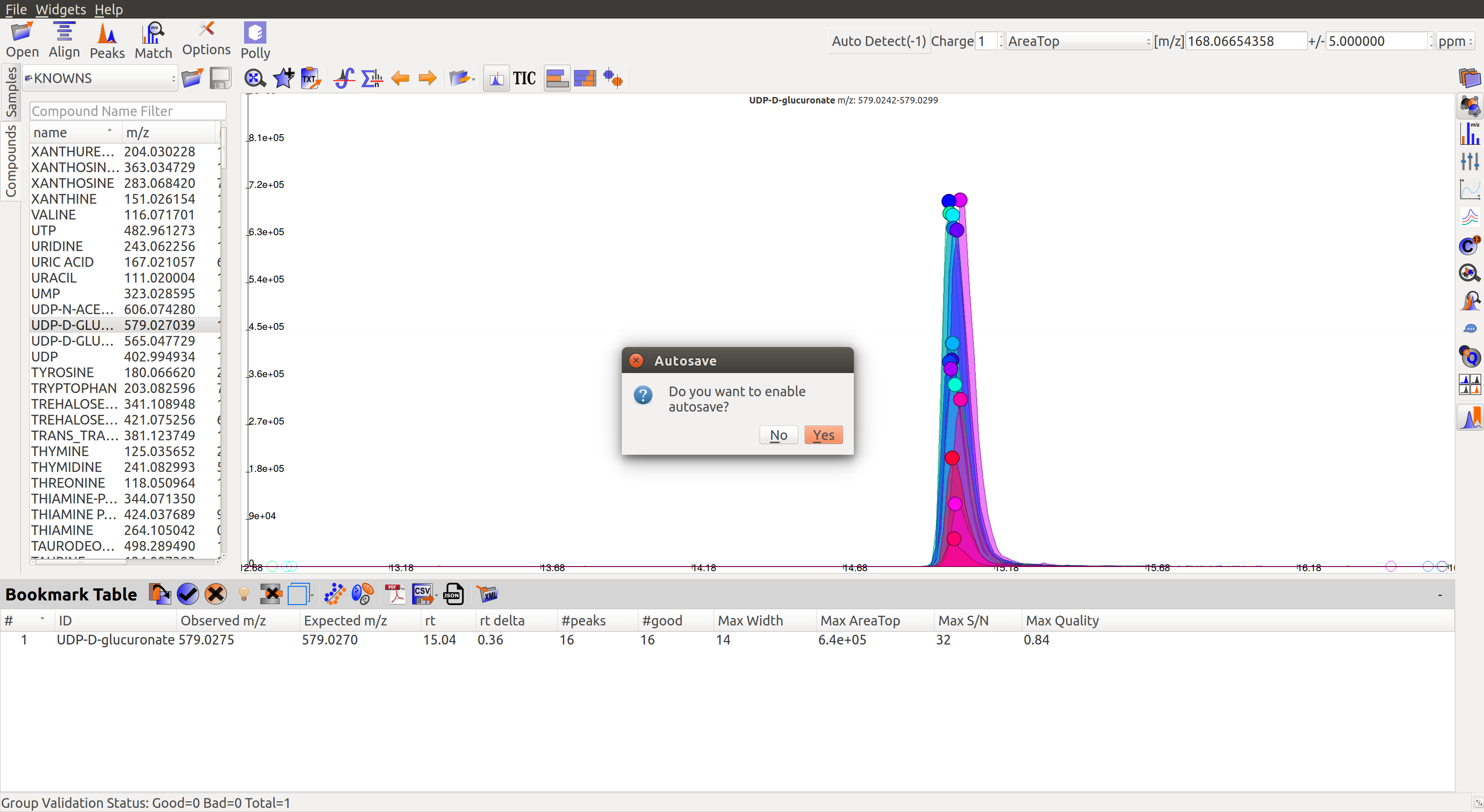
When the users select the first group, they would be asked if they would like to auto-save the state of the application. This feature allows the users to go back to their curated peaks if they so wish in future.
Qualifying peaks as good or bad is explained in the next few sections.
2. Automated Peak Curation
El-MAVEN can automatically select high intensity and high quality groups. This workflow is called automatic peak curation. To enable this workflow users have to click on the peak detection widget present in the top left of the window. Upon clicking the peak detection widget  the following dialog box will open.
the following dialog box will open.
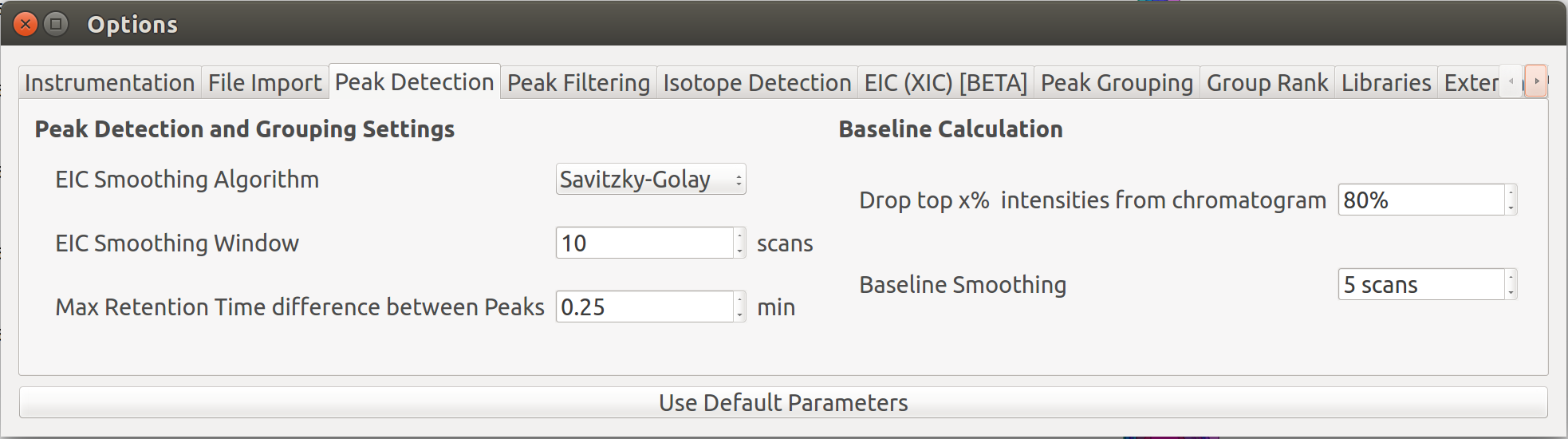
Users can read more about the peak detection widget here.
Upon selecting the default parameters, users can click on Find Peaks to select the most important peaks. Once the peak detection is completed, a peak table shows up at the bottom of the window.
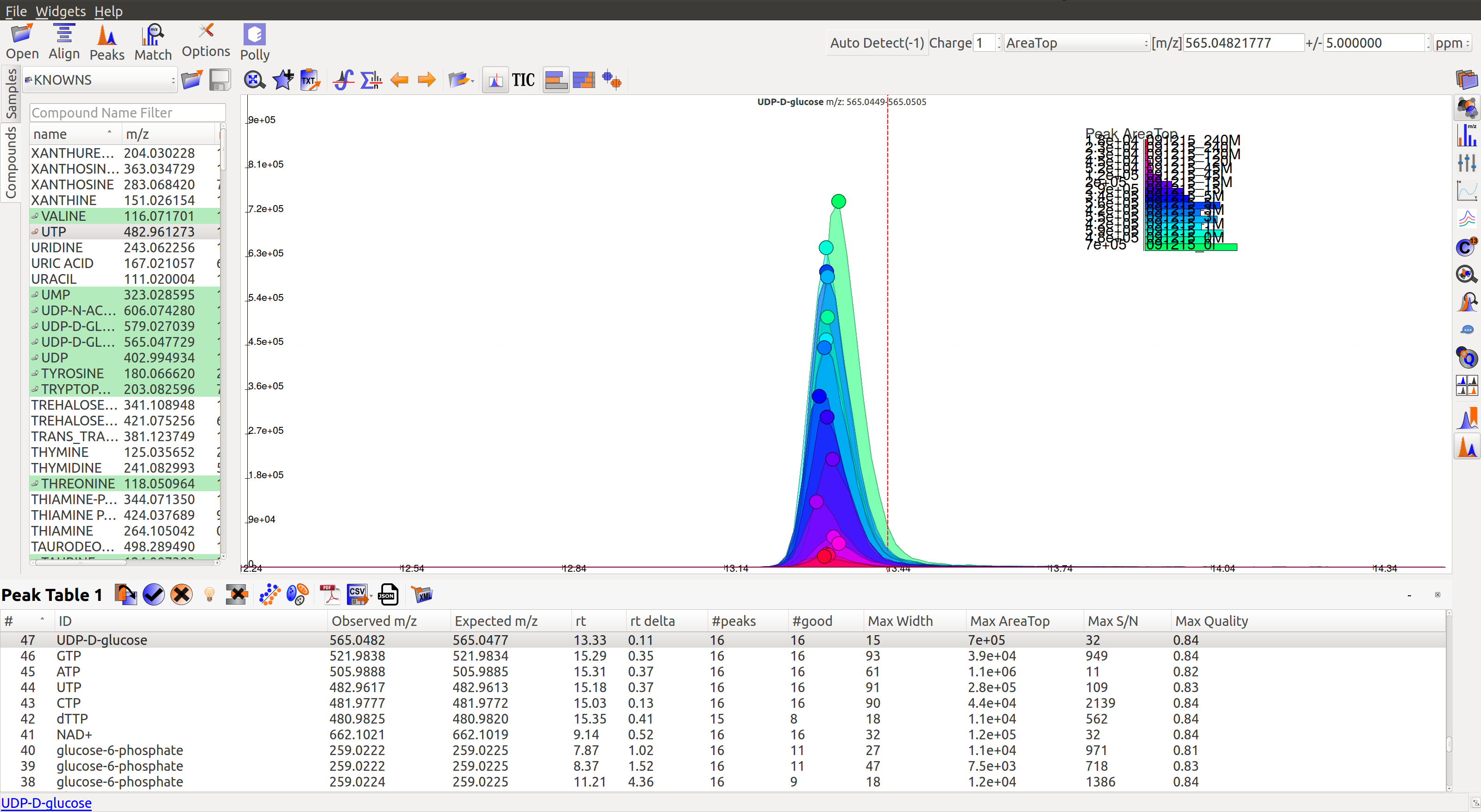
Users can now iterate over these peaks by marking them as good or bad by clicking on the good or bad buttons present in the peak table as shown below.
Guidelines for Peak Picking¶
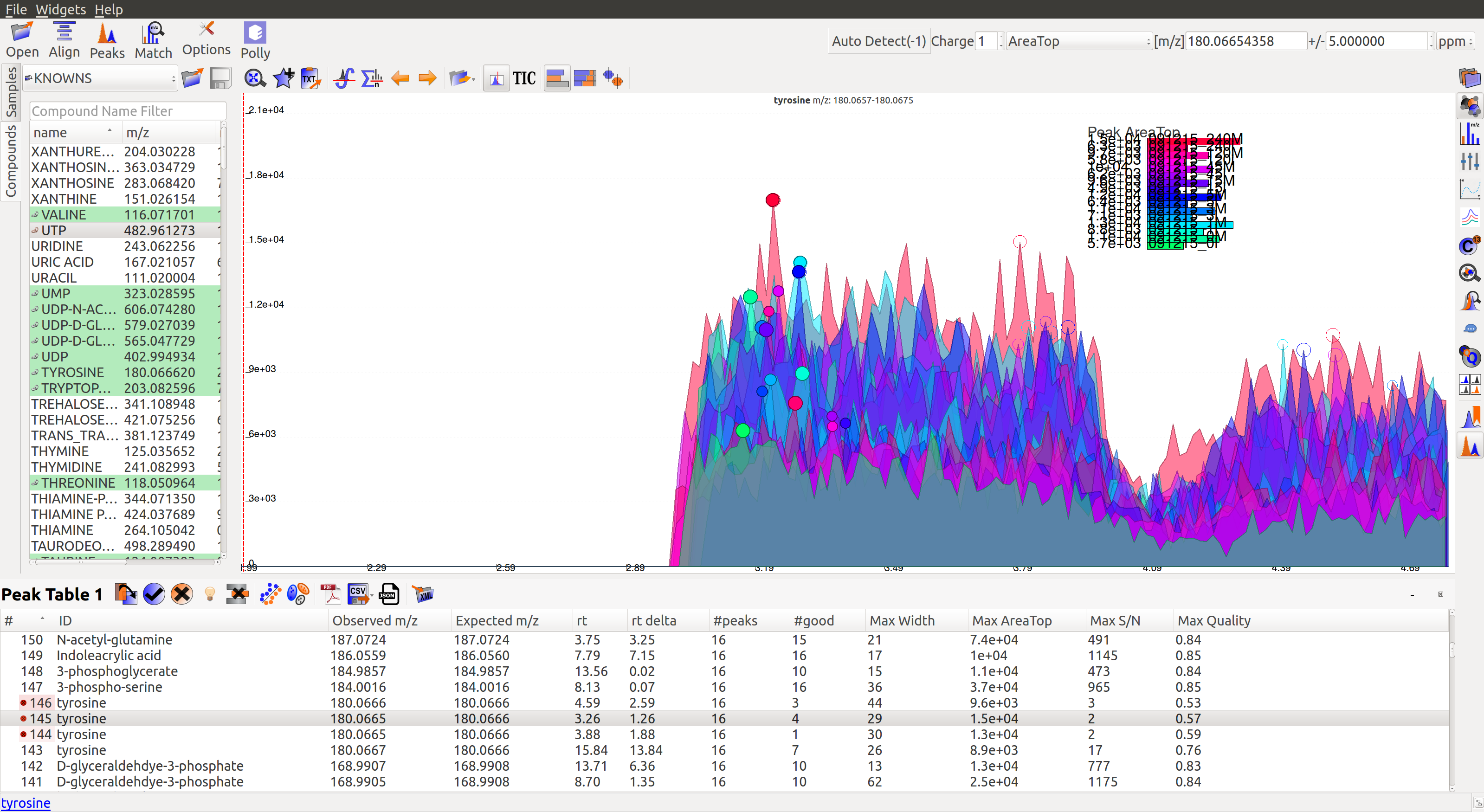
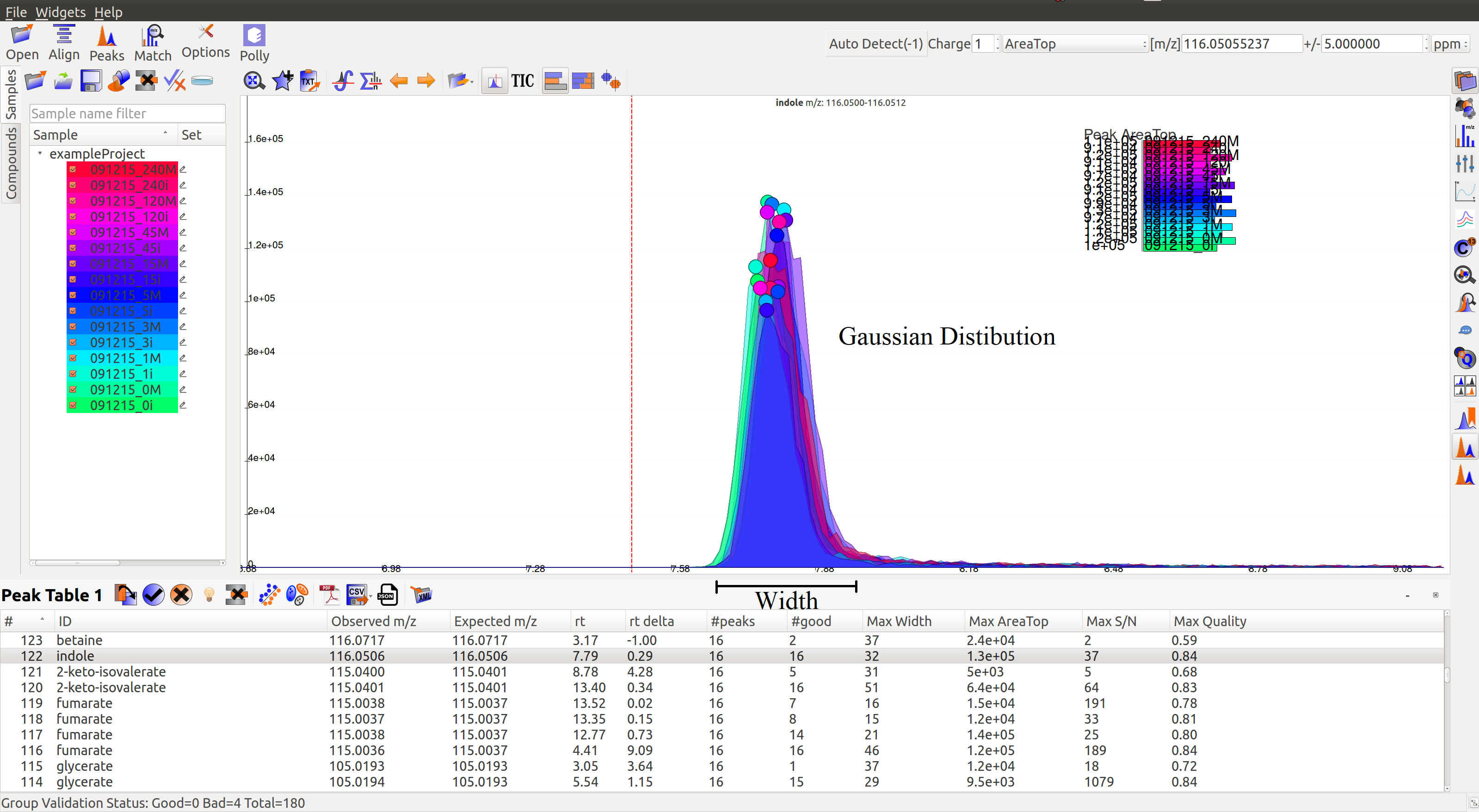
- A peak’s width and shape are two very crucial things to look at while classifying a peak as good or bad. A peak’s shape should have a Gaussian distribution and width should not be spread across a wide range of retention time.
- Peak Intensities for a group are plotted as bar plots for all the samples. These bar plots have heights relative to the other samples.Thus, for a good peak the intensities should be high.
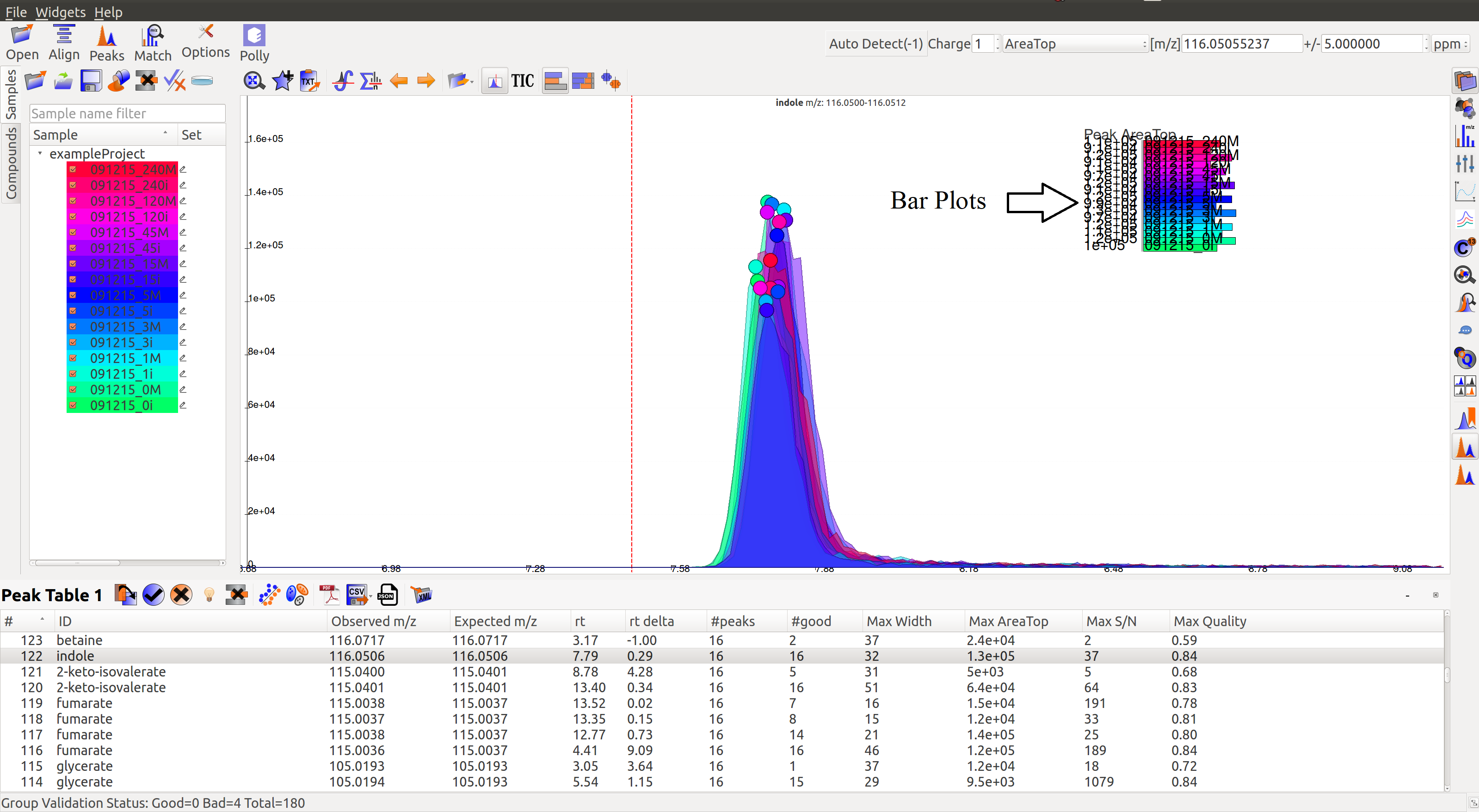
- Intensity Barplot heights should be higher for all the samples than Blank samples. We use intensities of Blank samples to set our group baseline. Blank intensities are used to calibrate intensity values across zero concentration.
- A good peak should have standards with varying intensity in a particular fashion (increasing or decreasing).
- Quality Control (QC) samples give us information about the quality of the data, i.e., it assesses reproducibility and software performance. Samples whose intensities and concentrations are already known are used as QCs to determine if the instrument is working as expected. Values (and scales) can be calibrated using QCs.
- If peak groups of a particular metabolite are separated apart (not aligned well) then we should use stringent alignment parameters to overcome this problem.
- For a particular metabolite, let’s say if it has n number of groups, then the group which is much closer to the above guidelines should be selected as a good peak. Multiple groups can also be selected in case of ambiguity (if retention time information is not provided).
A good peak would look similar to the following peaks:
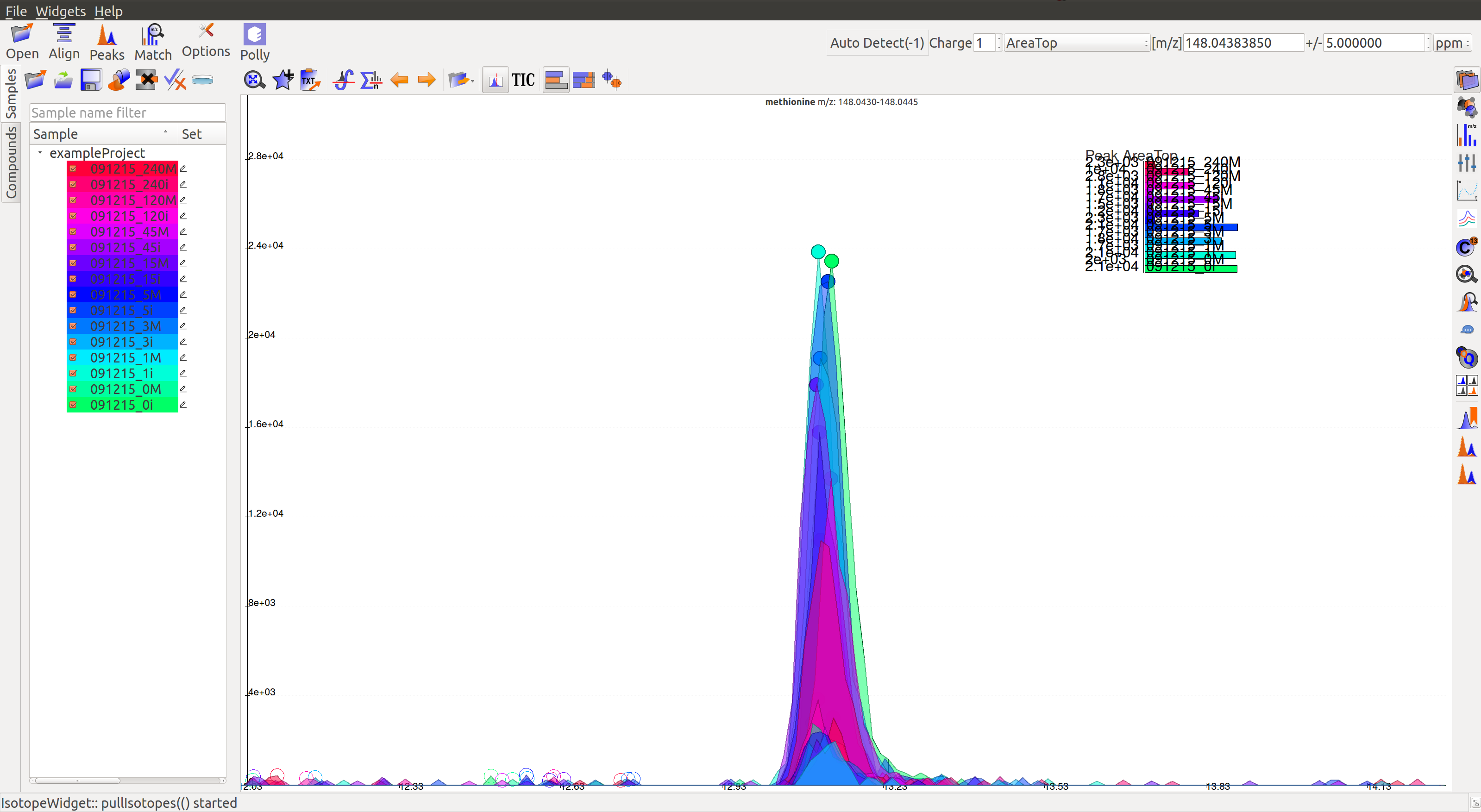
- Gaussian shape
- Perfect grouping, narrow retention time
- Good sample intensities
- Low blank intensities
- QCs look good
- An observable trend in intensity bars of standards, as well as samples.
Some examples of bad peaks are given below:
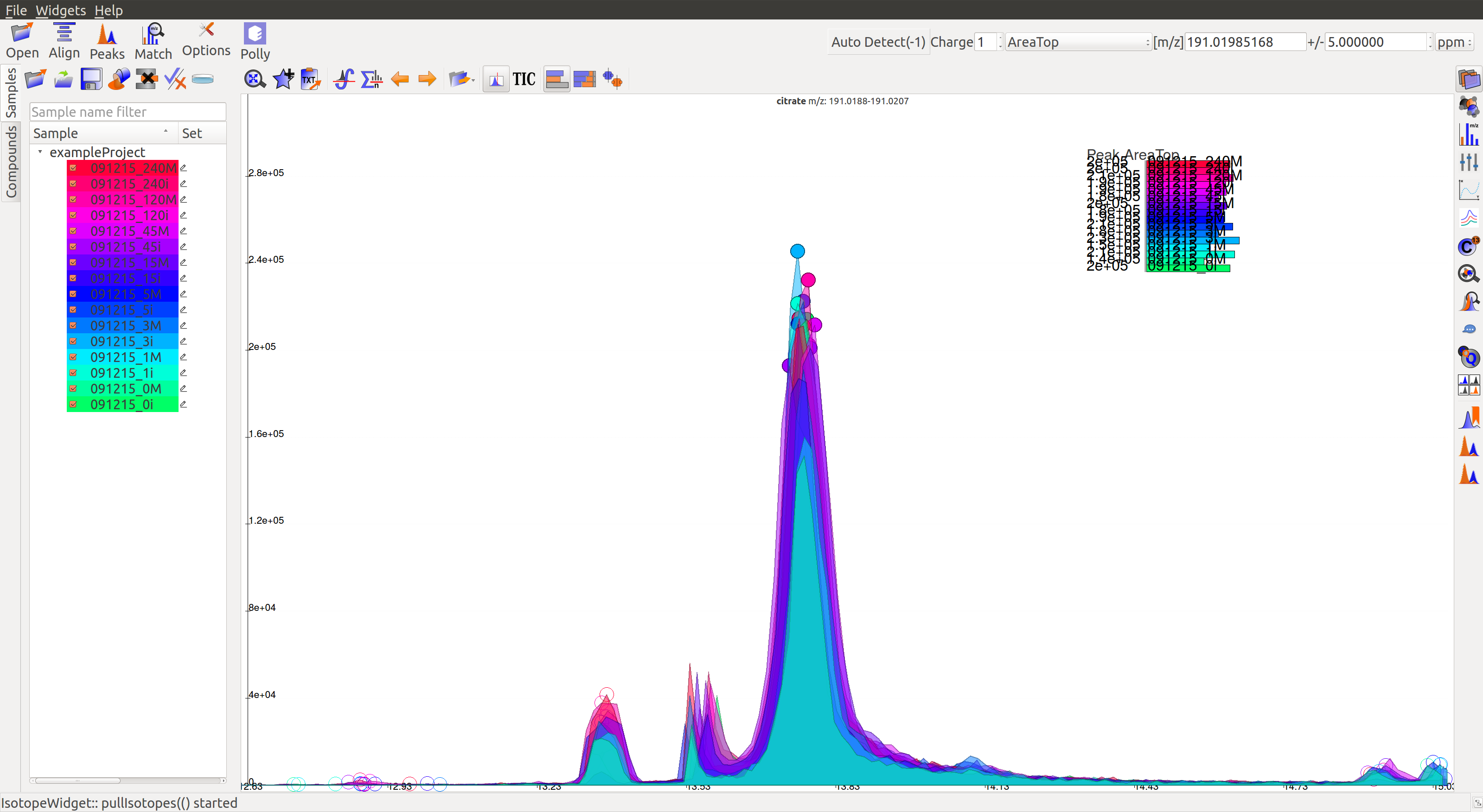
- The peaks do not have a Gaussian shape. Low intensity peaks are not grouping well. QC intensities (10^4) are too high with respect to the low sample intensities (10^2), which are very close to the noise level.
- The peaks have a good Gaussian shape. But the blank intensity bars are high. All the sample intensity bars are shorter or roughly equal to the blank intensities, implying that the peaks are noisy. This should be marked bad if better groups of the same metabolite are available.
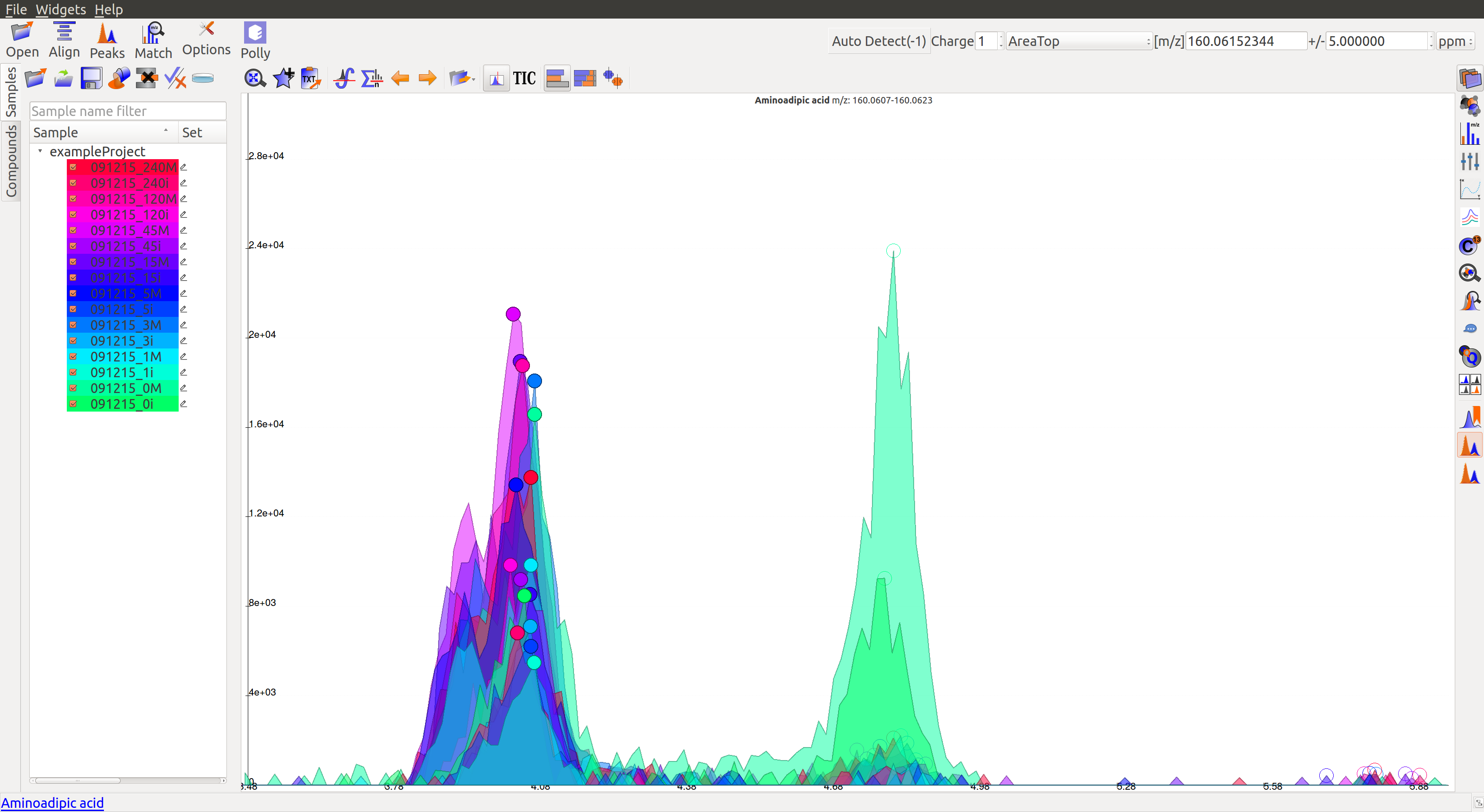
- The intensity levels are high. The blank intensities are lower. However, the peaks are spread over a long range of retention time, have poor grouping, and have forward trailing peaks. If the signal to noise ratio was improved, this peak would probably not be detected.
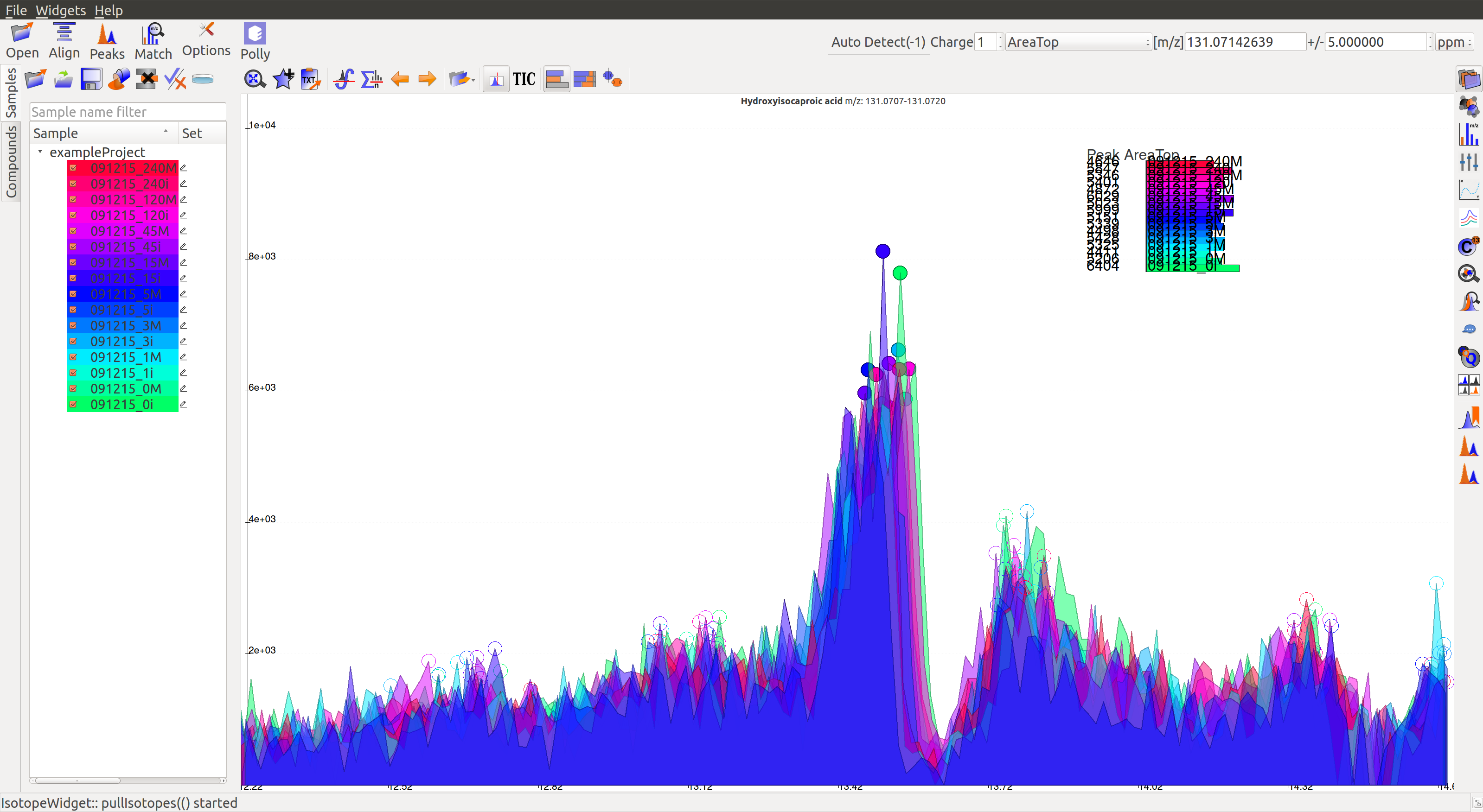
- In the following image, many sample intensities are missing from the intensities bar plots. Peaks do not have a Gaussian shape, nor good grouping. These peaks are probably noise which have been wrongly annotated. The blank intensities are high as well.
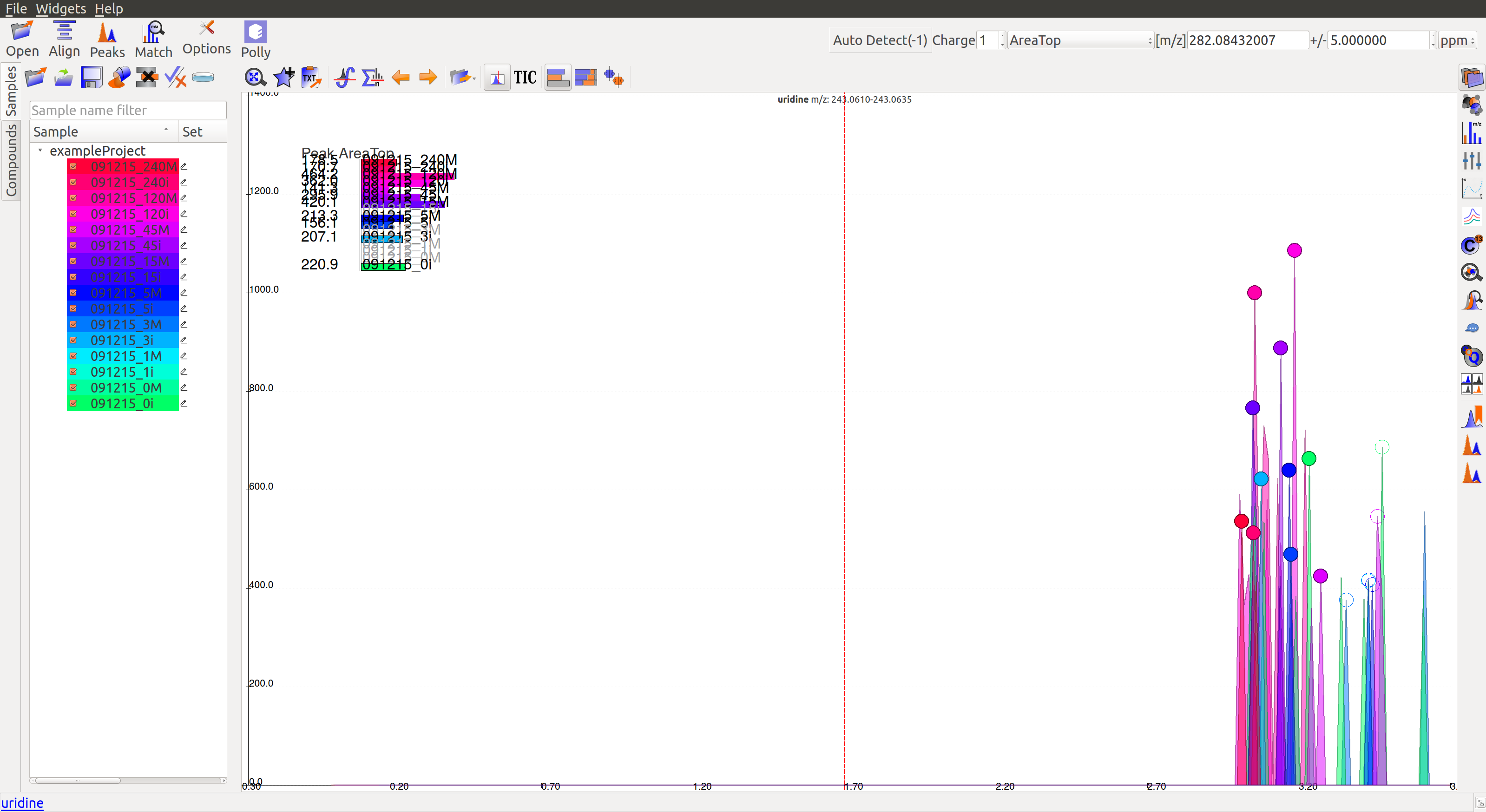
- This is a noisy group. There are no discrete peaks visible in the image. The X-axis is crowded with noise. The peak shape is sharp, triangular, or line-like; not Gaussian. The intensity levels are high, but so are the noise levels.
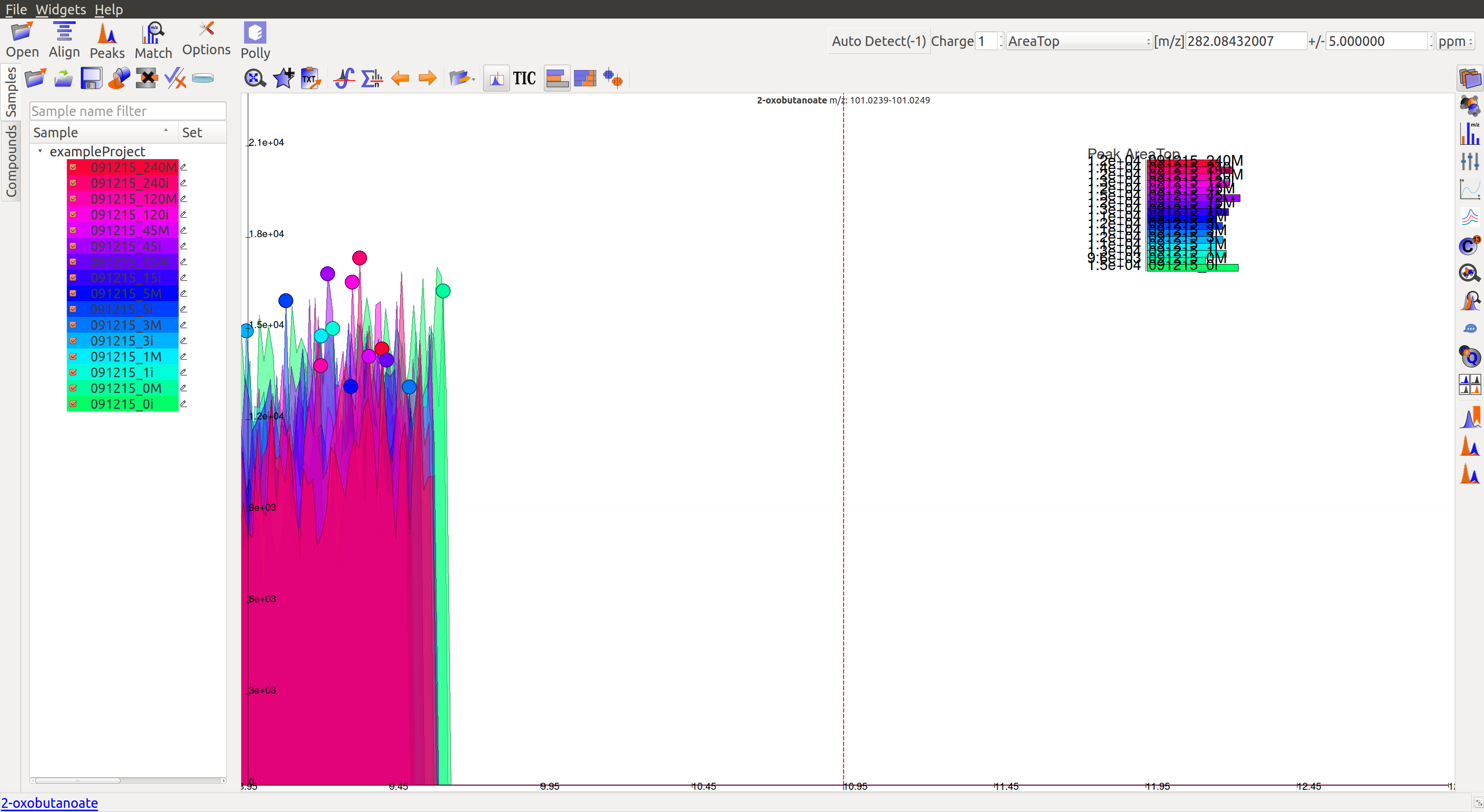
- The peaks don’t have a Gaussian shape, and are also noisy. The intensity values are very low.
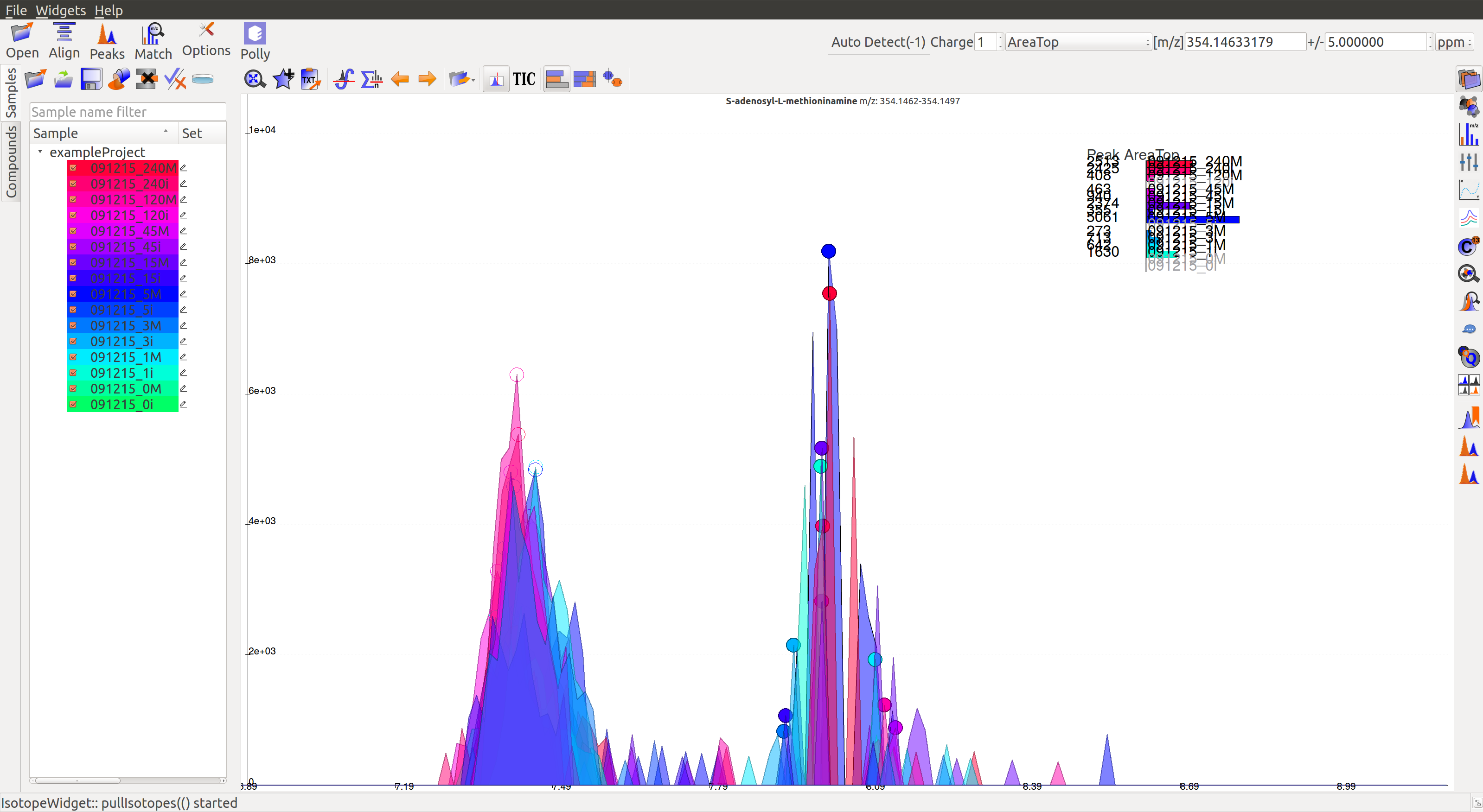
- For low intensity groups like this, the peak characteristics can be determined by zooming in.
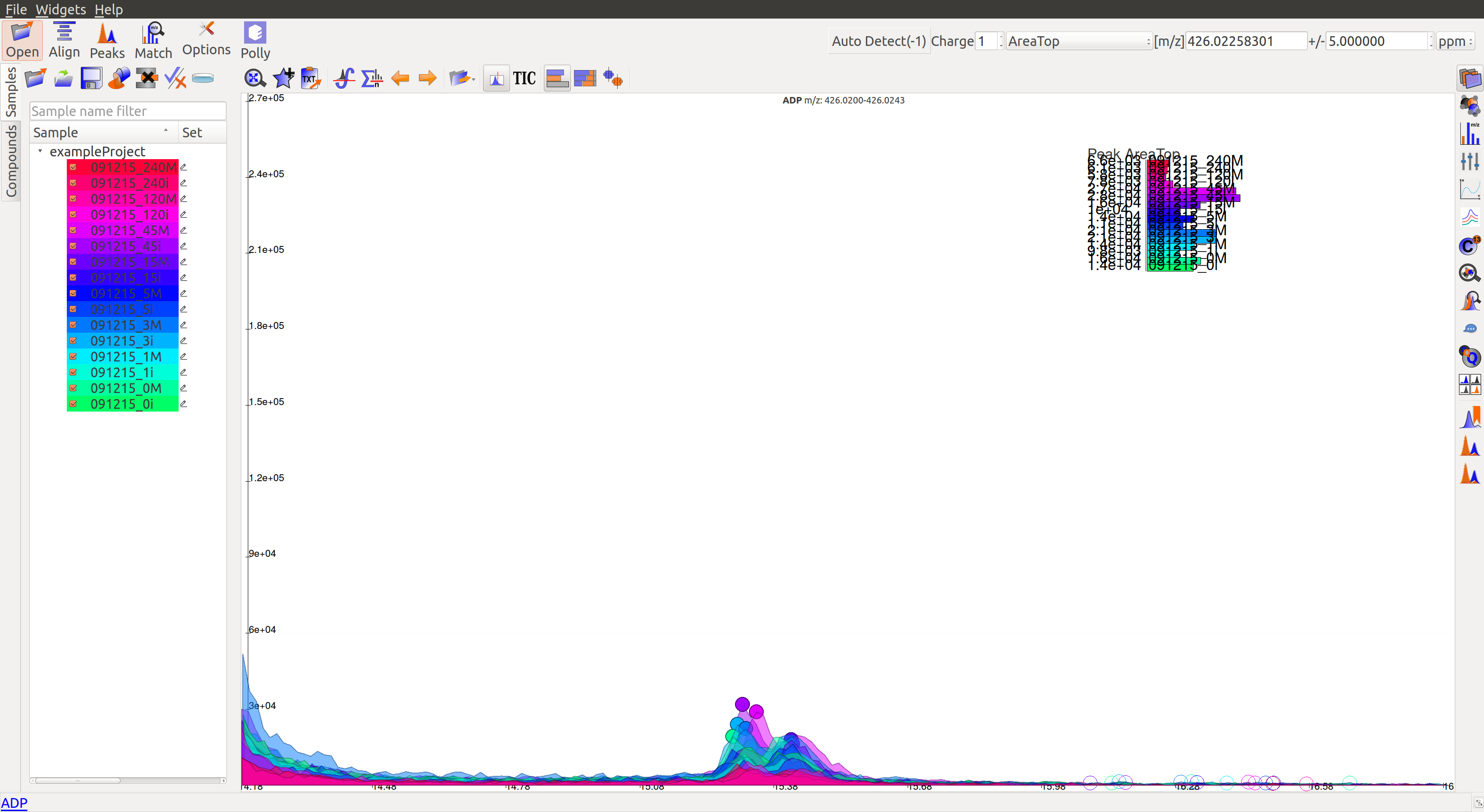
The mouse can be used to select the area of the peak as shown below
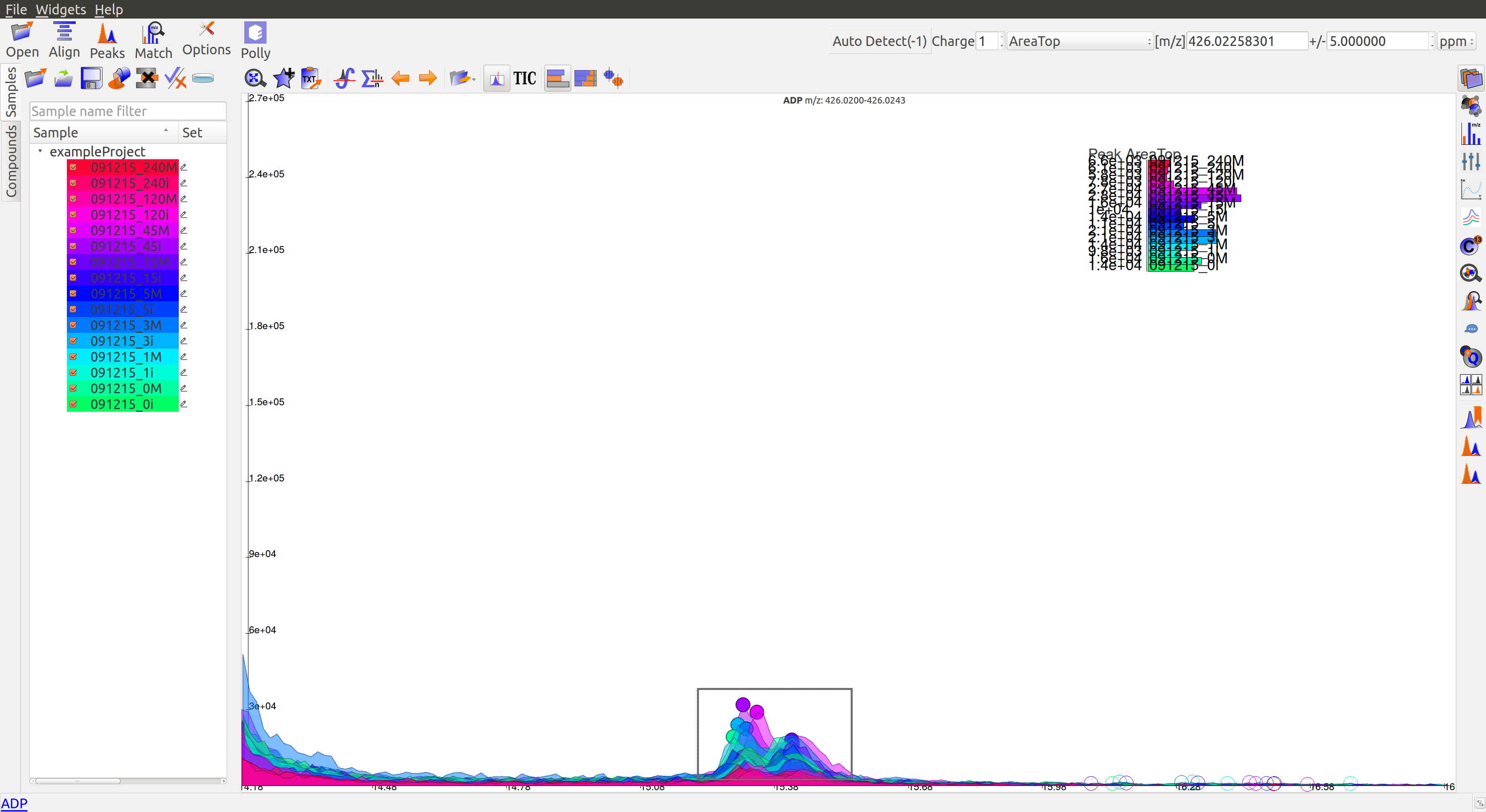
On zooming, it will be easy to make a decision on peak quality
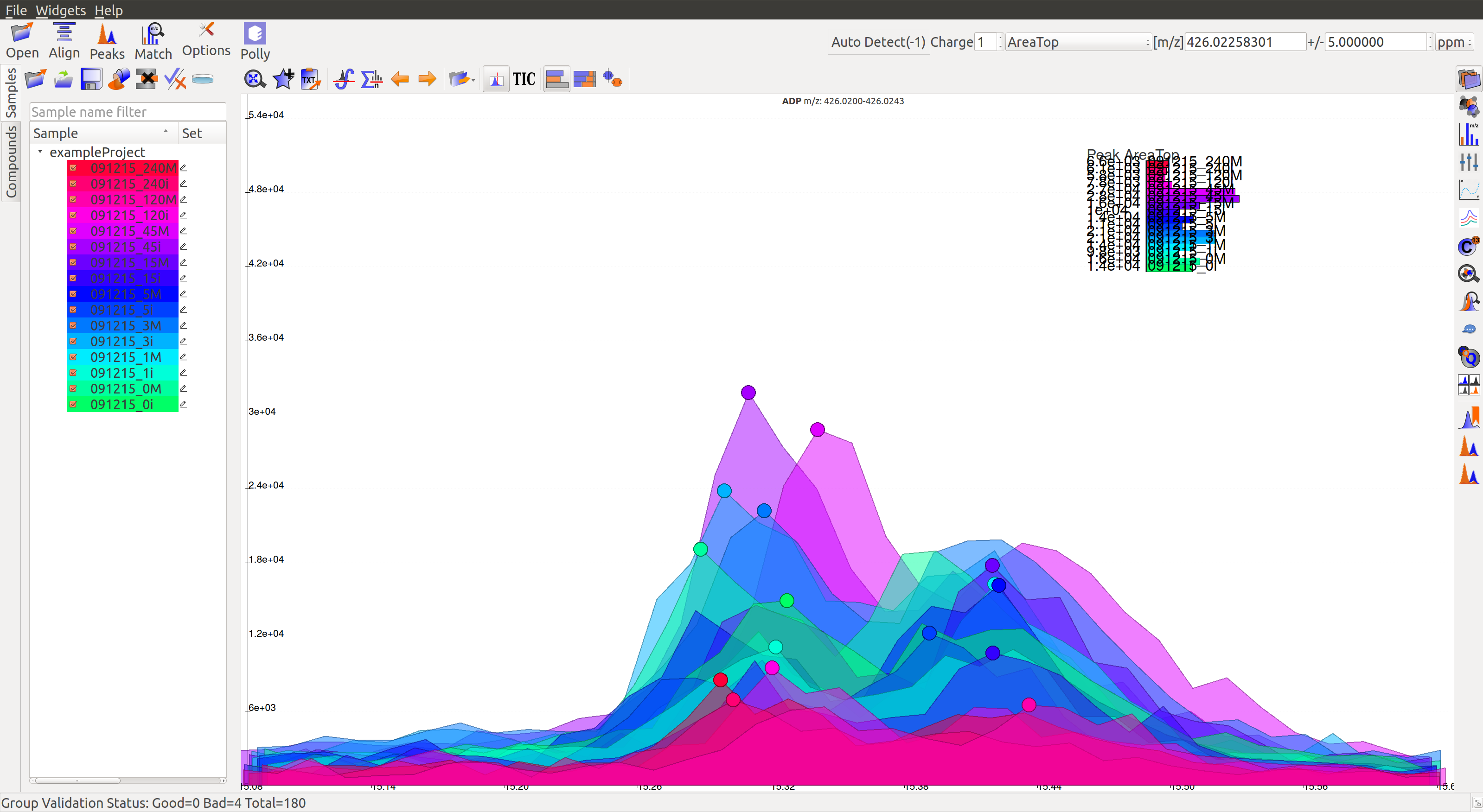
The user can mark any ambiguous peaks as good, and can review all such peaks later in the process.
Export¶
There are multiple export options available for storing marked peak data. Users can either generate a PDF report to save the EIC for every metabolite, export data for a particular group in .csv format, or export the EICs to a Json file as shown below.
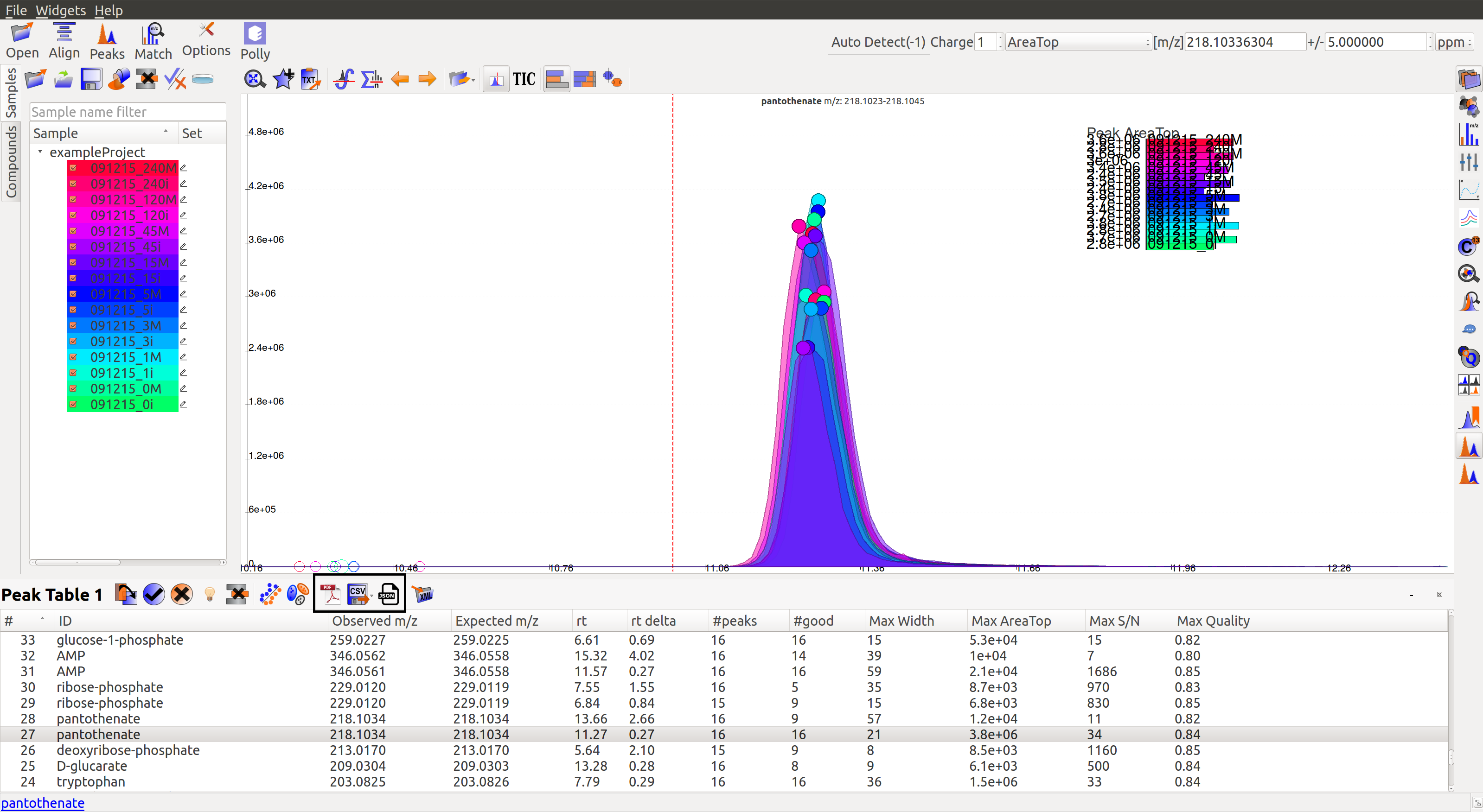
Users can select All, Good, Bad or Selected peaks to export.
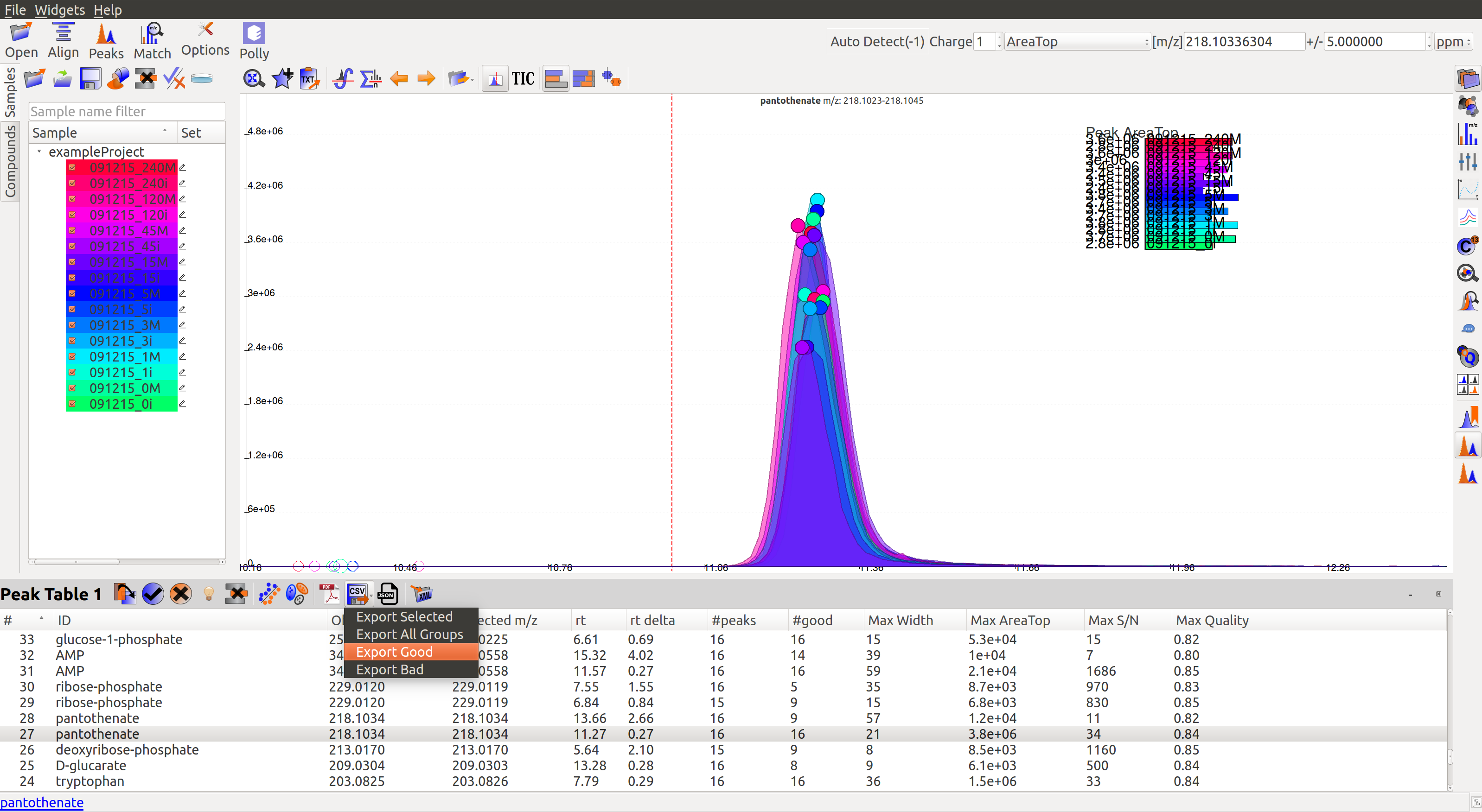
The Export Groups to CSV option  lets the users save the ‘good’/’bad’ labels along with the peak table. Users also have the option to filter out rows that have a certain label while exporting the table.
lets the users save the ‘good’/’bad’ labels along with the peak table. Users also have the option to filter out rows that have a certain label while exporting the table.
Generate PDF Report option  saves all EICs with their corresponding bar plots in a PDF file.
saves all EICs with their corresponding bar plots in a PDF file.
Export EICs to Json option  exports all EICs to a Json file.
exports all EICs to a Json file.
Another option is to export the peak data in .mzroll format that can be directly loaded into El-MAVEN by clicking on the Load Samples|Projects|Peaks option in the File menu. For this, go to the File option in the menu bar, and click on ‘Save Project’.